Search and Optimization
This is a Python library for Search and Optimization.
Welcome
This is a library for search and optimization algorithms. The basic topics are covered which include Descent Method, Stochastic Search, Path Search, MDP-related and RL related algorithms. By using this library, you are expected to see basic ideas behind the algorithms through simple but intuitive visualizations.
Hope you can have fun in search and optimization! Any problems with the algorithm or implementation or other problems please feel free to contact me!
Table of Contents
Requirements
The implementation is quite simple and intuitive. If you can use conda, you are ready to go! If not, the requirements are:
Python 3.8.x
numpy
matplotlib
How to use
clone this repo.
git clone https://github.com/ruipengZ/Search-and-Optimization.git
Install the required dependency
Using conda
conda env create -f conda.yml
Using pip
pip install -r requirements.txt
Run certain algorithms in the library then see the visualization.
Algorithms
This repo covers the basic topics in Search and Optimization, including Descent Method, Stochastic Search, Path Search, MDP-related and RL related algorithms.
Descent Method
Descent Method in general starts at some initial point and tries to get to the local minimum in descendent way. It includes gradient descent, Newton’s Method and conjugate descent.
Gradient Descent
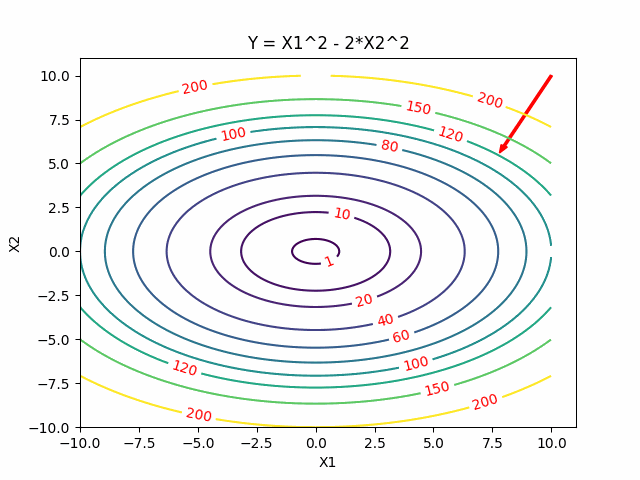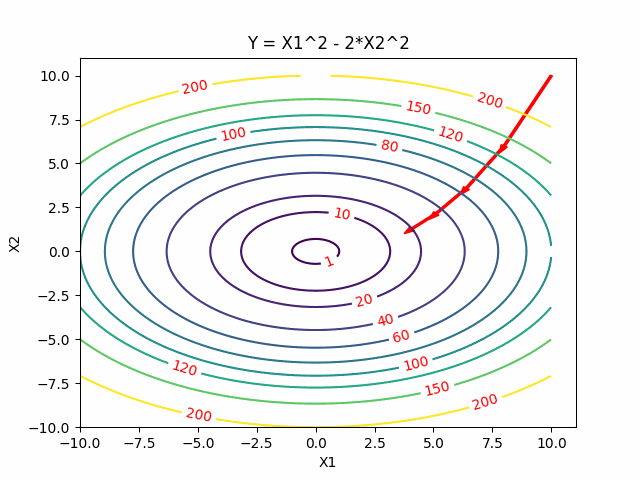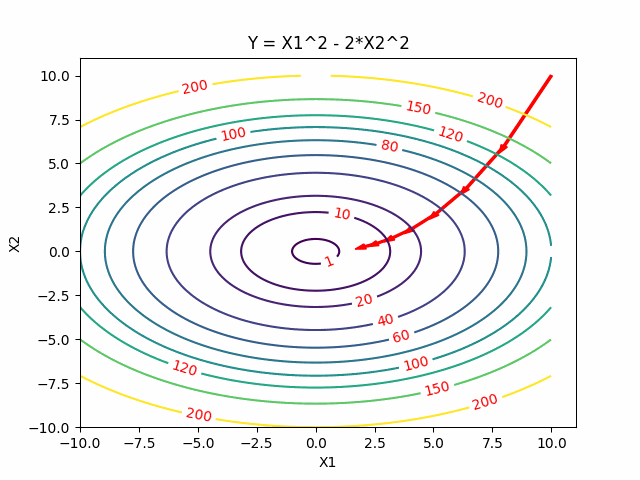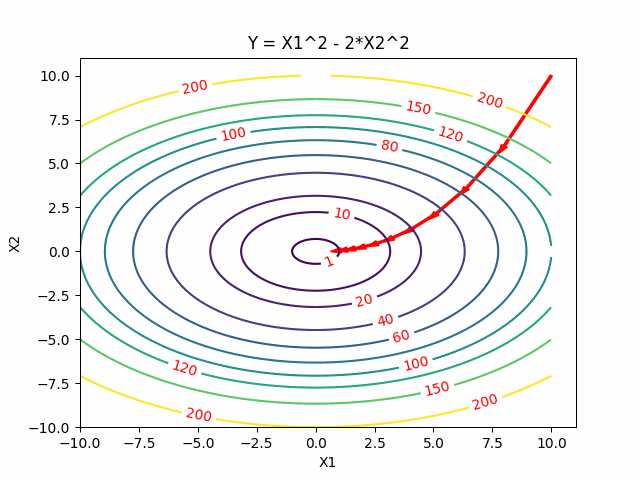
Gradient Descent is widely used in optimization and machine learning areas because its simple calculation. It tries to take a small step towards the gradient descent direction to minimize the function.
Here are the one and two dimensional example visualization for gradient descent.
One Dimensional Case
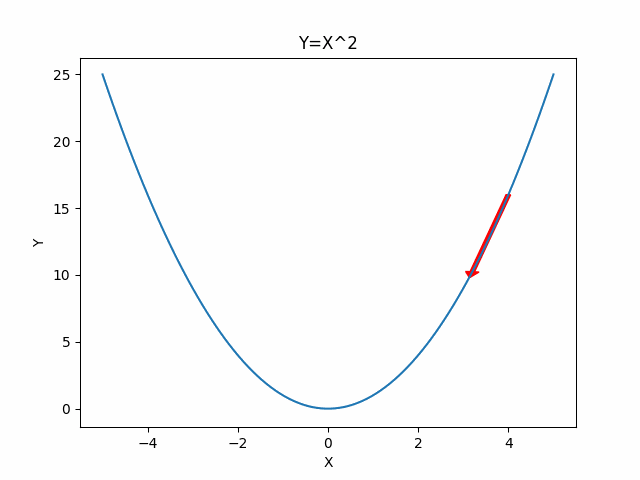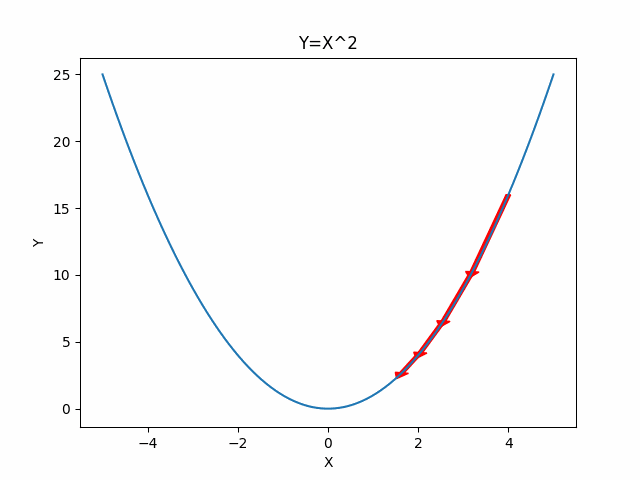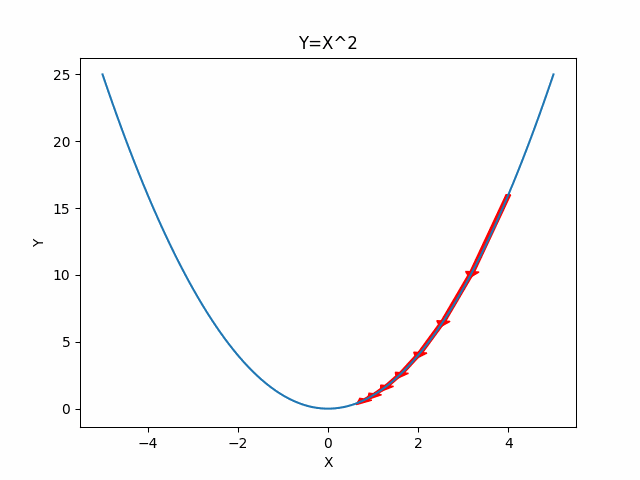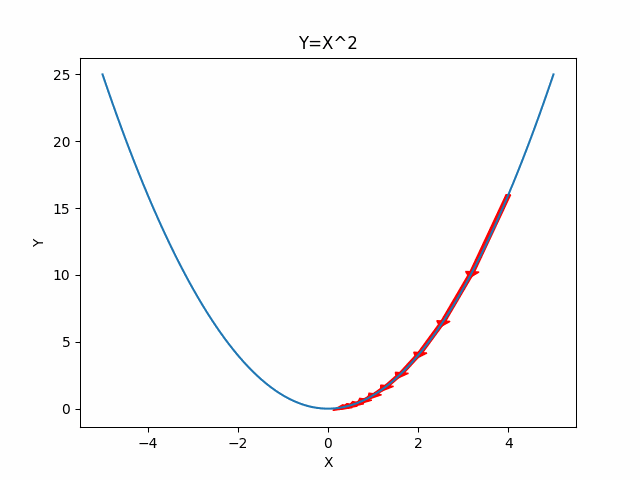
Two Dimensional Case
Newton’s Method
Gradient Descent uses the first derivative as guess of the function. Newton’s Method, instead uses a sequence of second-order Taylor approximations of around the iterates which gives rise to a faster descent process.
One Dimensional Case
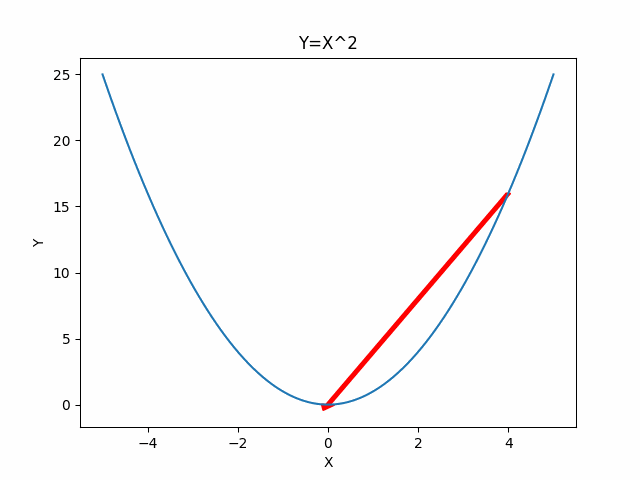
Two Dimensional Case

However fast and do not need a step size (learning rate), Newton’s Method has some drawbacks and caveats:
The computation cost of inverting the Hessian could be non-trivial.
It does not work if the Hessian is not invertible.
It may not converge at all, but can enter a cycle having more than 1 point.
It can converge to a saddle point instead of to a local minimum
Reference:
See details on https://en.wikipedia.org/wiki/Newton%27s_method_in_optimization
Conjugate Descent
For quadratic problems, we can do better than generic directions of gradient. In Gradient Descent if we take the steepest descent, we always go onthogonal in every step. Can we go faster? Yes, Newton’s method gives us a faster one. But at the same time, we also want to avoid calculating the inversion of certain matrics. Conjugate gradients give us a better way to perform descent method because they allow us to minimize convex quadratic objectives in at most n steps and without inverting the matrics.
One Dimensional Case
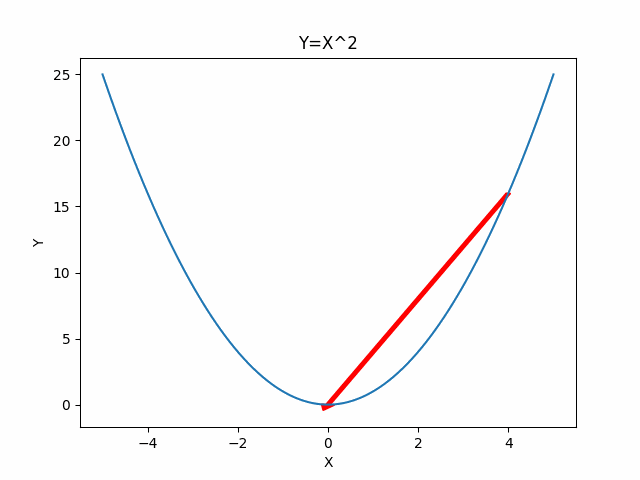
Two Dimensional Case
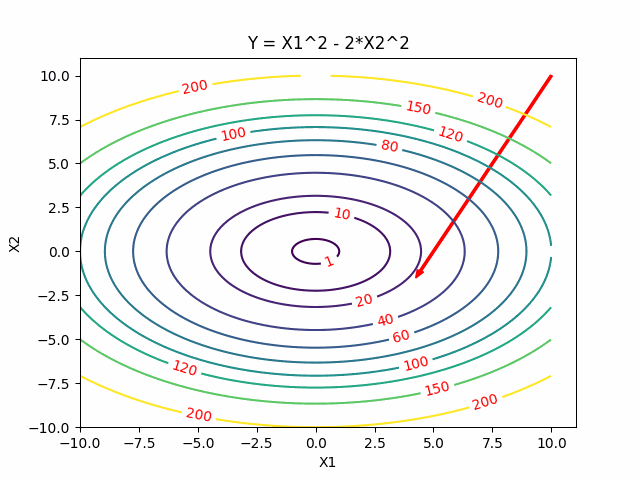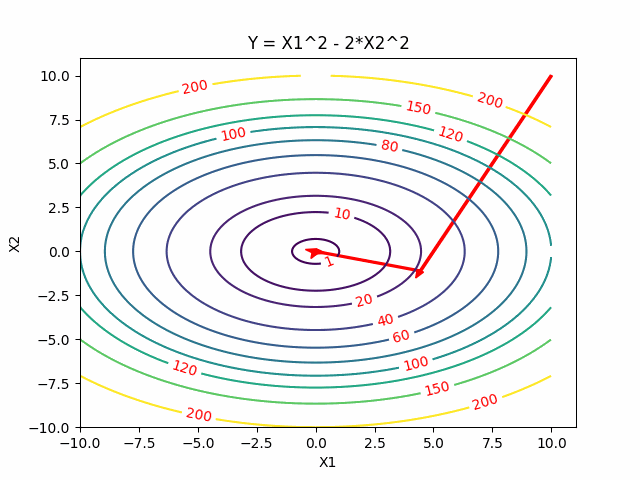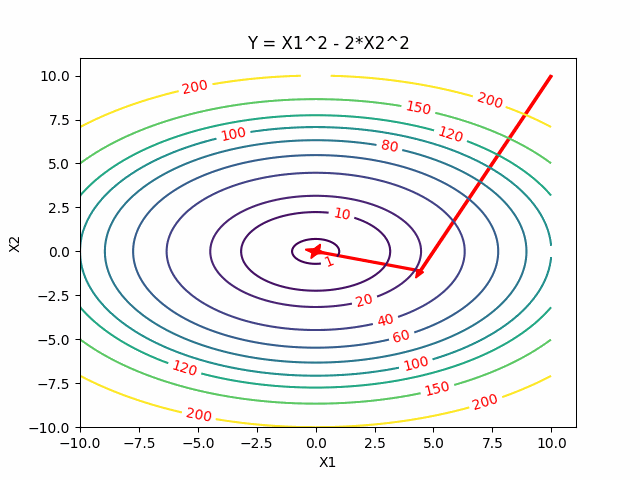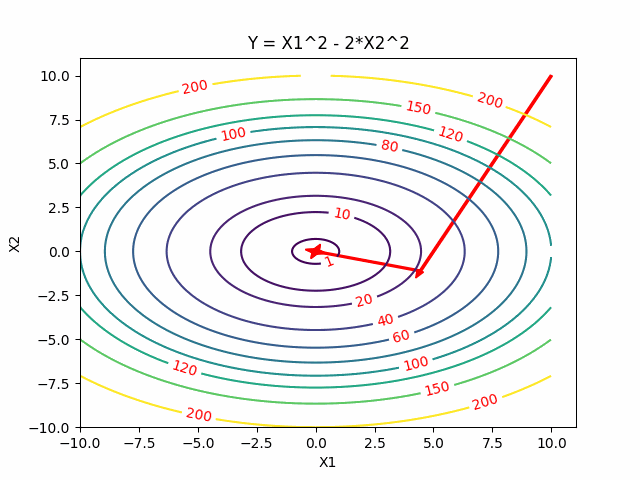
Reference:
you can find more details in the reference slides
http://www.cs.cmu.edu/~pradeepr/convexopt/Lecture_Slides/conjugate_direction_methods.pdf
Comparison of Descent Methods
We can compare the visualization of the above three descent methods as follows:






As you can see, Gradient Descent slowly move to the minimum whereas Conjugate Descent and Newton’s Method is faster. In the two dimensional case above, we can observe that Conjugate Descent can be regarded as being between the method of Gradient Descent (first-order method) and Newton’s method (second-order method).
Stochastic Search
In some cases, we do not want to or cannot calculate the first or second derivate of the function. Or there are numerous local minimas of the function and the descent methods not work well. Instead, we can introduce some randomness into the optimization. Here we will cover algorithms including Simulated Annealing, Cross Entropy Method and Search Gradient.
Simulated Annealing
Intuitively, Simulated Annealing is to start from one point, dive into the function and walk randomly, go downhill when we can but sometimes uphill to explore and try to jump out of this sub-optimal local minimum. We expect to gradually settle down by reducing the probability of exploring.
For problems where finding an approximate global optimum is more important than finding a precise local optimum in a fixed amount of time, simulated annealing may be preferable to exact algorithms like descent methods.
Here is the visualization of Simulated Annealing:
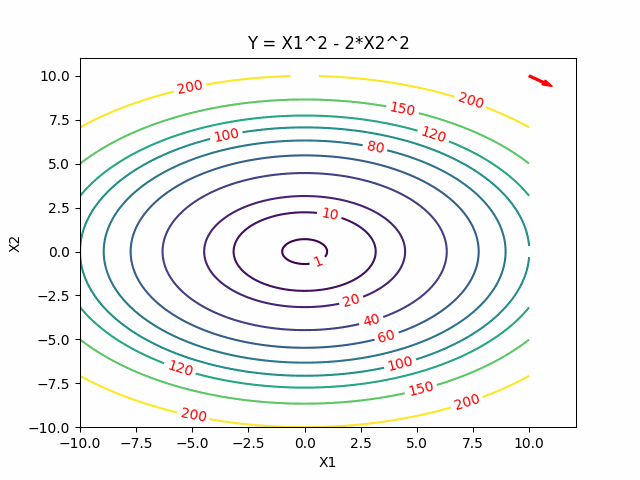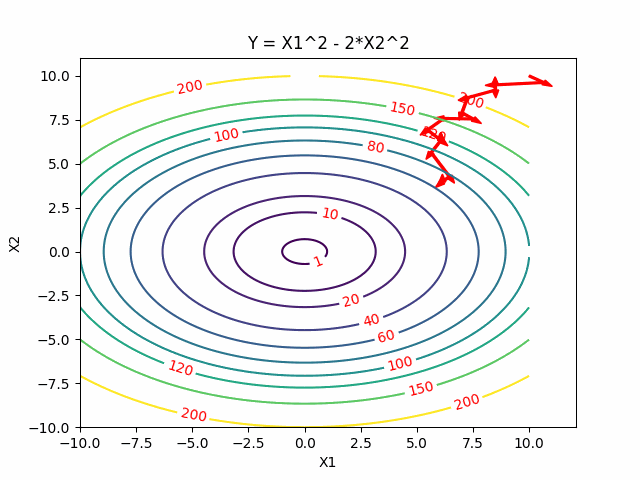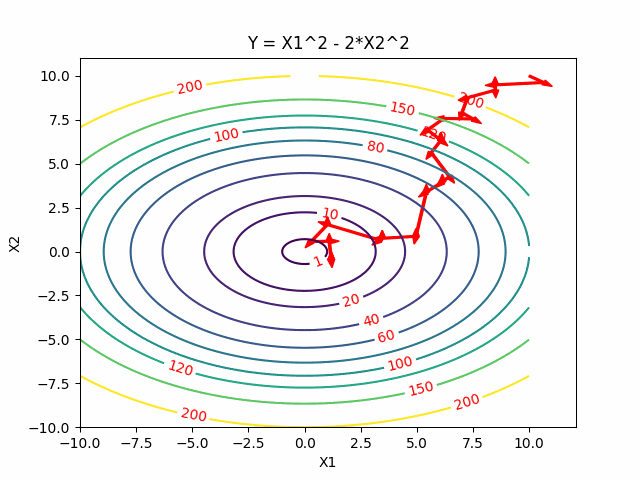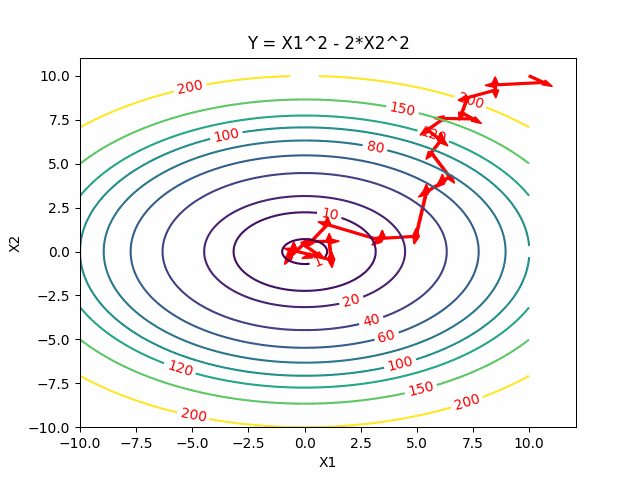
Reference:
https://en.wikipedia.org/wiki/Simulated_annealing
Cross Entropy Methods
Instead to take one sample of the function, Cross Entropy Methods sample a distribution. The key idea behind that is that finding a global minimum is equivalent to sampling a distribution centered around it.
Cross Entropy Methods first start with an initial distribution (often a diagonal Gaussian), and then select a subset of samples with lower function values as elite samples. Then update the distribution to best fit those elite samples.
Here is the visualization of CEM, where red points are elite samples.
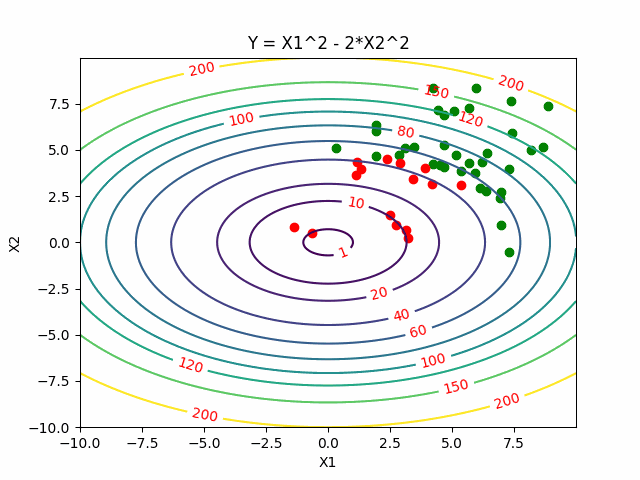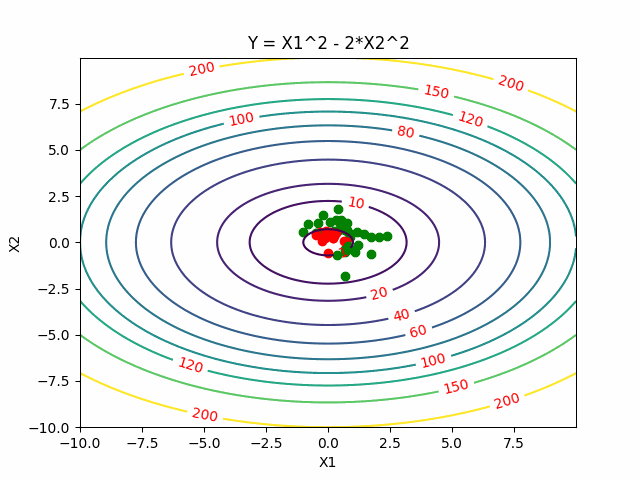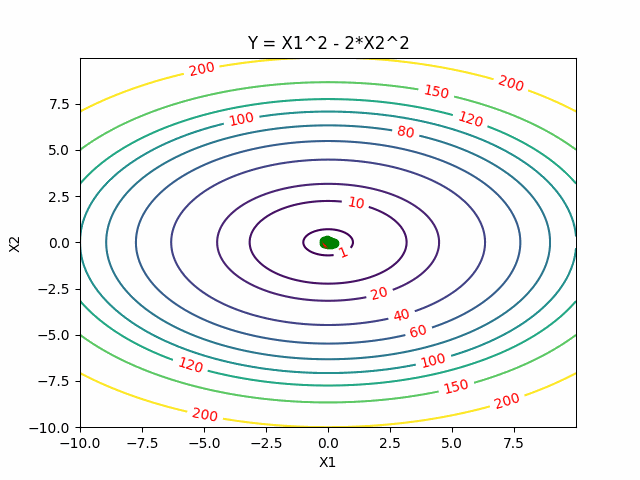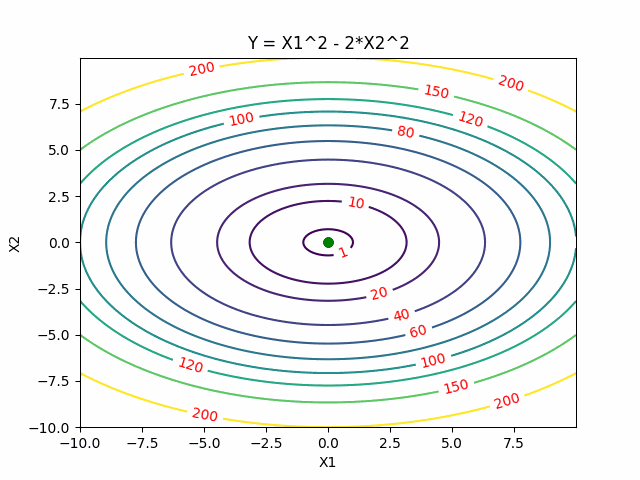
Search Gradient
In high dimensions, it can quickly become very inefficient to randomly sample. Ideally, we can use the derivative of the expectation of function value on the distribution we sampled, so that we can move the distribution in the direction that imroves the expectation. So Search Gradient borrows the idea of Gradient Method to do stochastic search. The overall algorithm uses this idea combined with log techniques, see reference for details.
Here is the visualization of Search Gradient:

Reference:
“Natural Evolution Strategies” Wierstra et al. JMLR 2014
Path Search
As a pratical problem, Path Search can take on many forms, including shortest path searching, motion planing and playing game like zero-sum game between two players and so on. Here we present some of the useful algorithms.
A* Search
Path Searching Algorithms including DFS (Depth First Search), BFS (Breadth First Search), UCS(Uniform Cost Search) are formulated in terms of weighted graphs: starting from a specific starting node of a graph, it aims to find a path to the given goal node having the smallest cost (least distance travelled, shortest time, etc.). They maintains a tree of paths originating at the start node and extending those paths one edge at a time until its termination criterion is satisfied. Whereas these algorithms are all uninformed search: you don’t know where you are unless you happen to hit the goal, A* search is a informed search with heuristic function to measure how close you are to the goal.
Intuitively, it not only take account of the cost-to-come but also cost-to-go. We can see it as a special case of UCS whereas it uses the cost of real cost plus heuristic cost by adopting a heuristic function.
You can find more details with the reference.
Here is a visualization of a path searching process of A*. We start on the red star and the destination is blue star. Black grid are obstacles. Yellow cross are all the locations that have been searched and the final shortest path is red cross path.
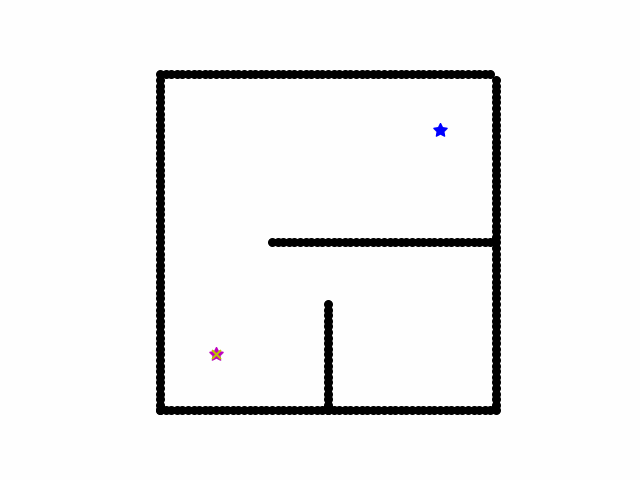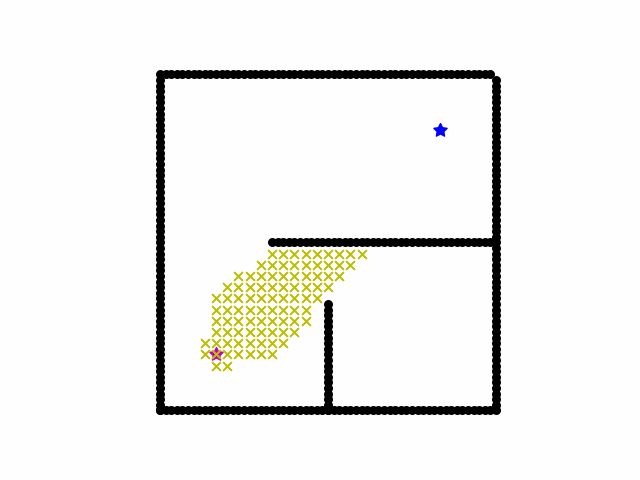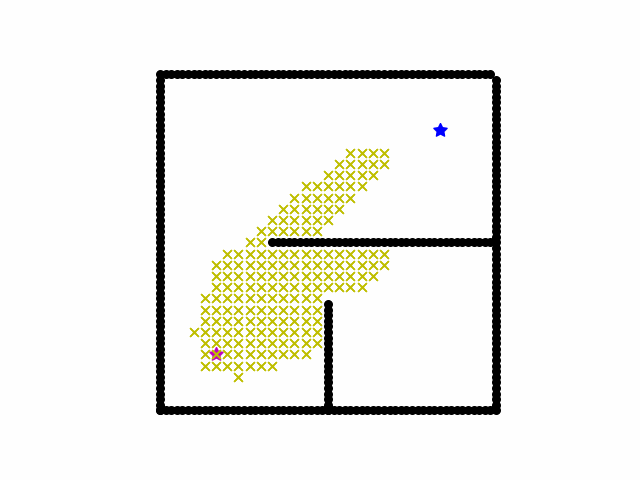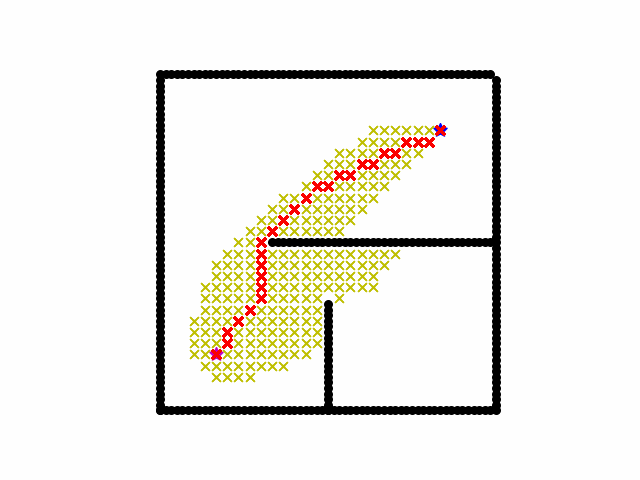
Reference:
https://en.wikipedia.org/wiki/A*_search_algorithm
RRT
A rapidly exploring random tree (RRT) searches a path by randomly growing a tree in the free space. Concretely, in each iteration, randomly sample a state from the free space. Then we find the node in the current tree nearest to the sampled state, and grow the tree at that node by a small step. Meanwhile, we periodically check if the goal is a small distance away from any node in the tree.
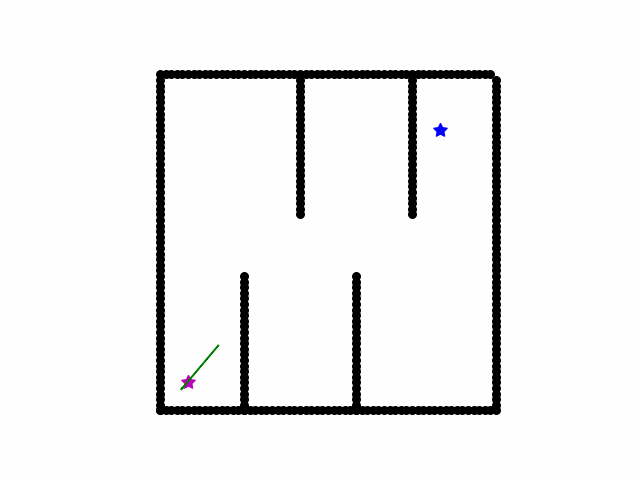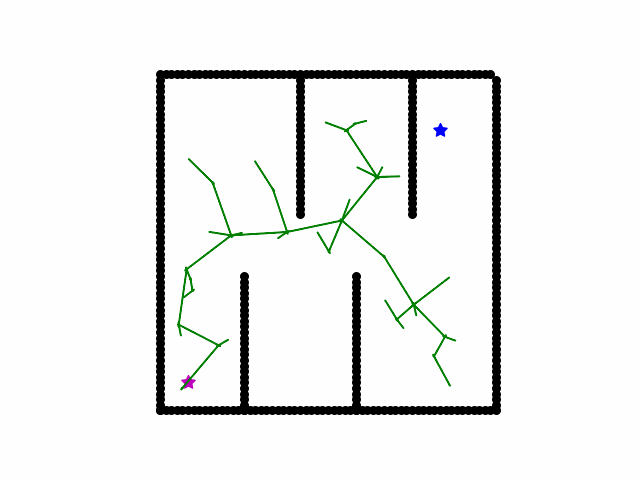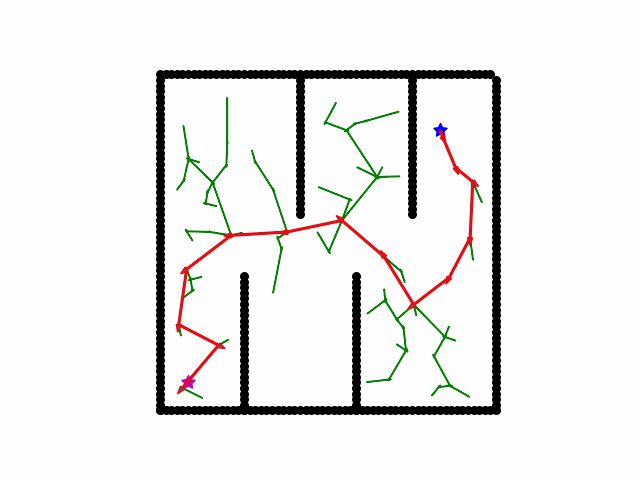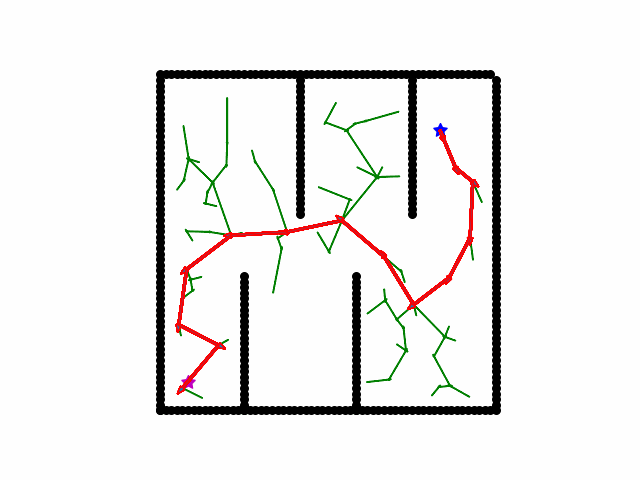
Minimax Search
Suppose we are playing games with another one in turn. At the end of the game, there are certain payoffs. In the game, we make every move to maximize our the benefit or value and the opponent tries to minimize it. We can use Minimax Search on this max-min-player game to calculate every value of a tree node and then make the best move.
Here is the visualization for Minimax Search. The max players are the green nodes and blue nodes are the min players. At the end of the game, there are payoffs as grey nodes. Minimax calculate every nodes’ value and the choice from bottom to top, visualized as orange texts and arrows. Finally as the root max player, the red nodes and arrows are showed as how we should play the game to get the maximum benefit.
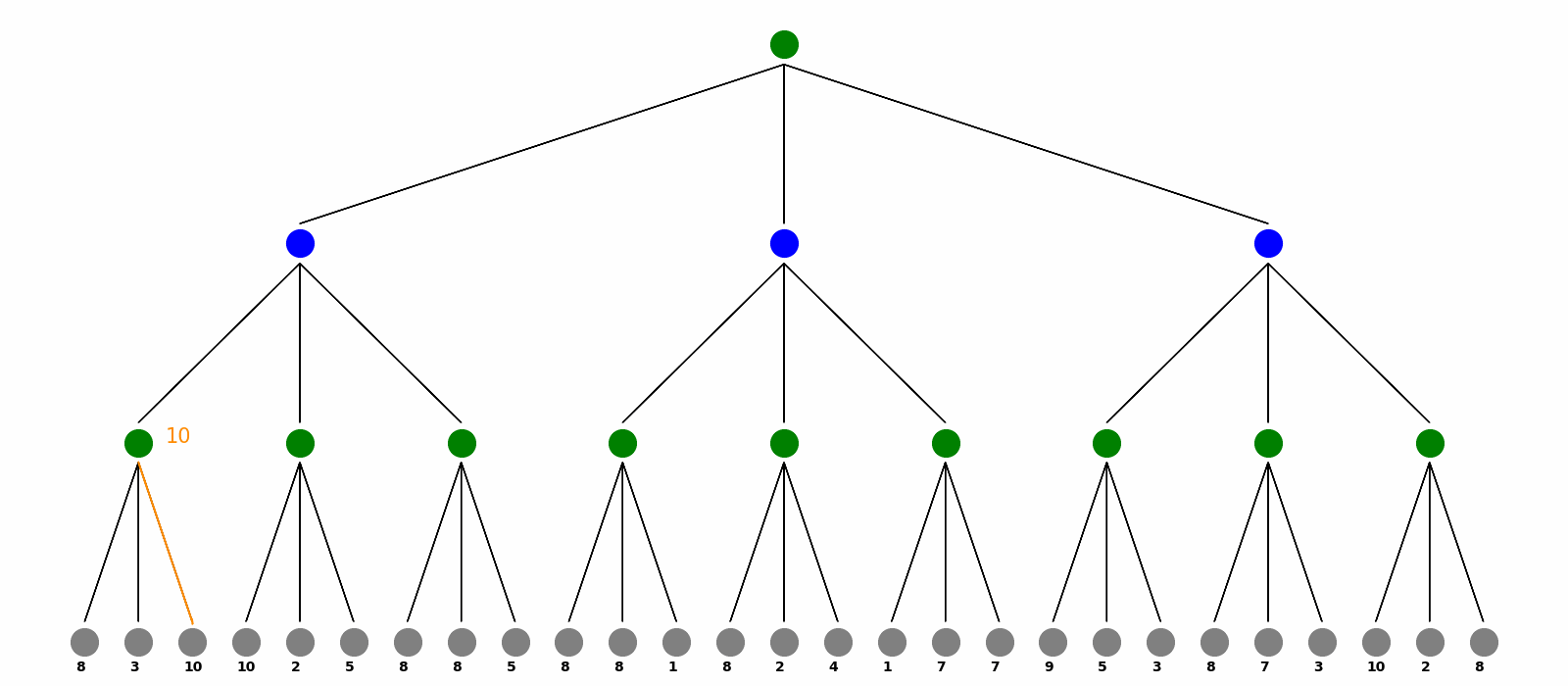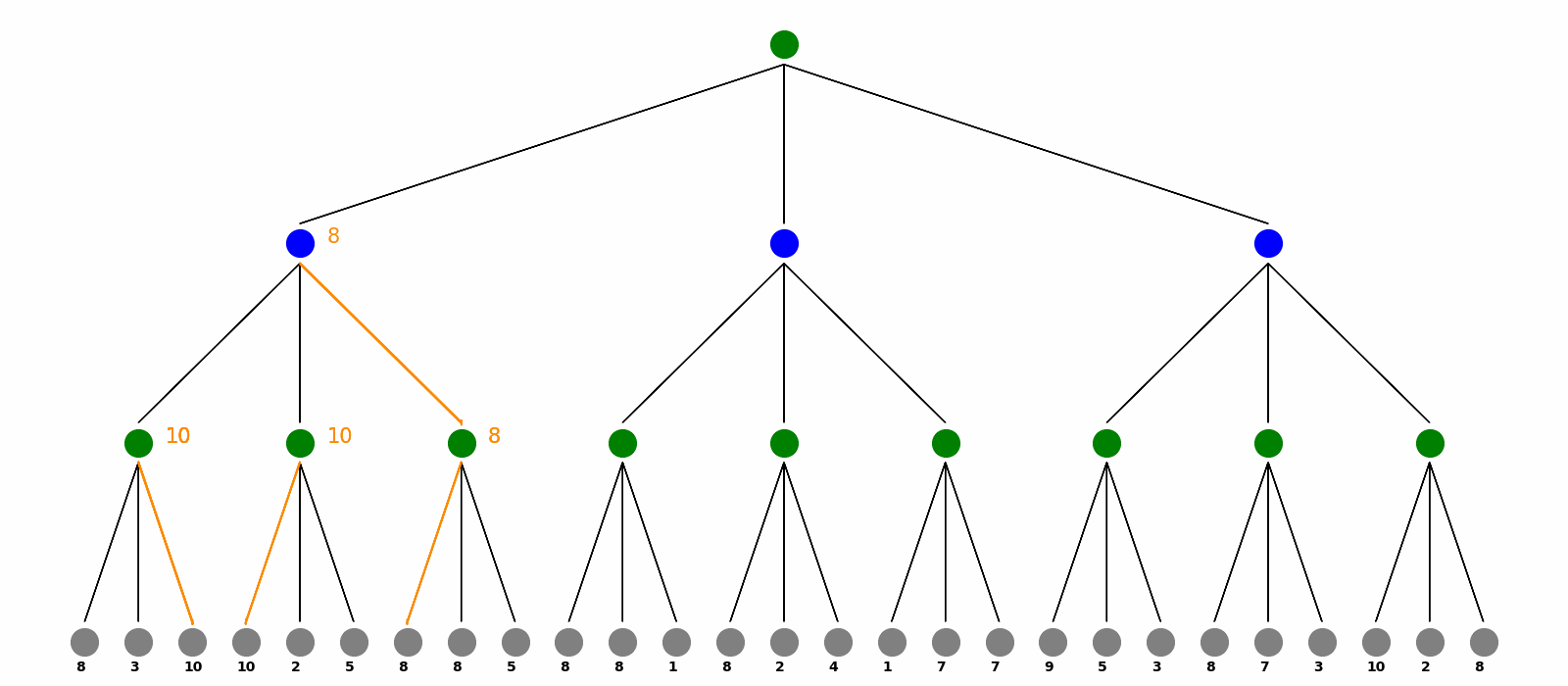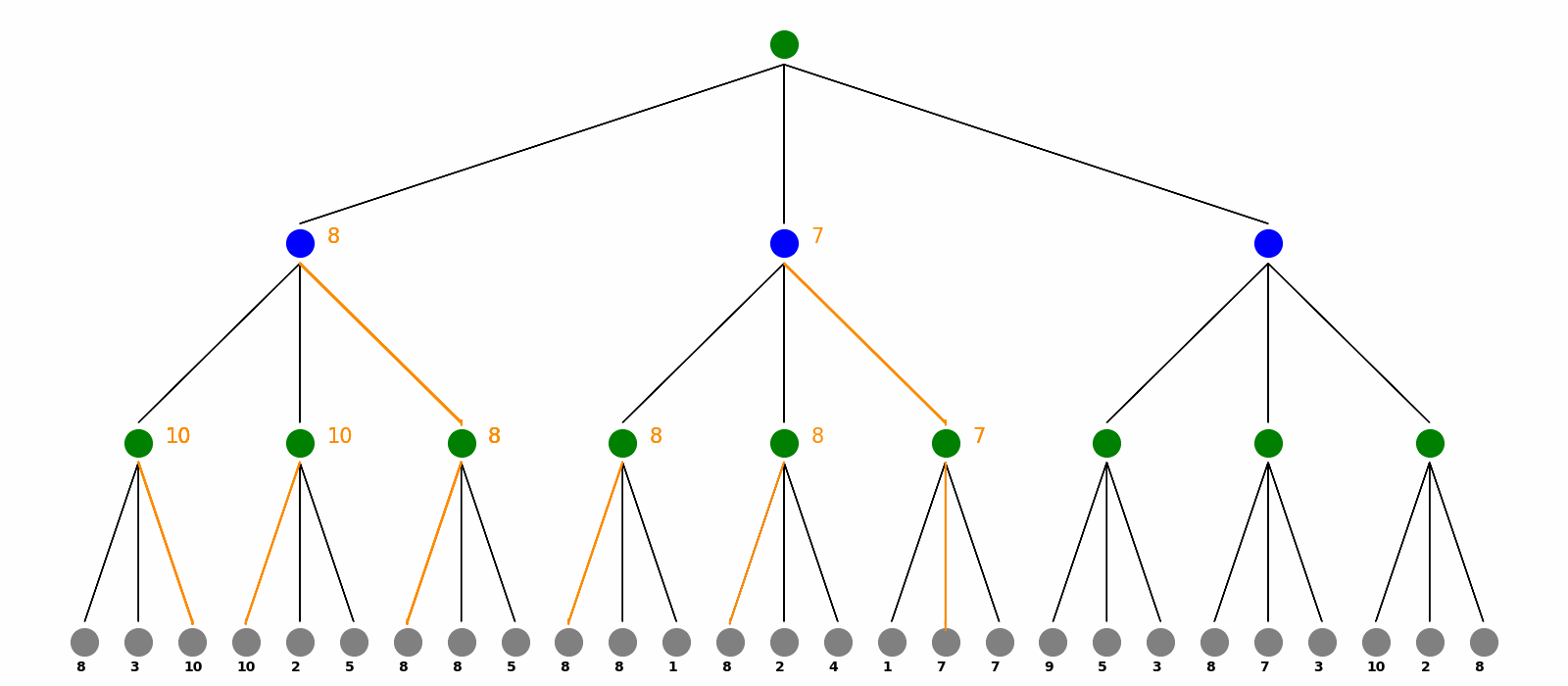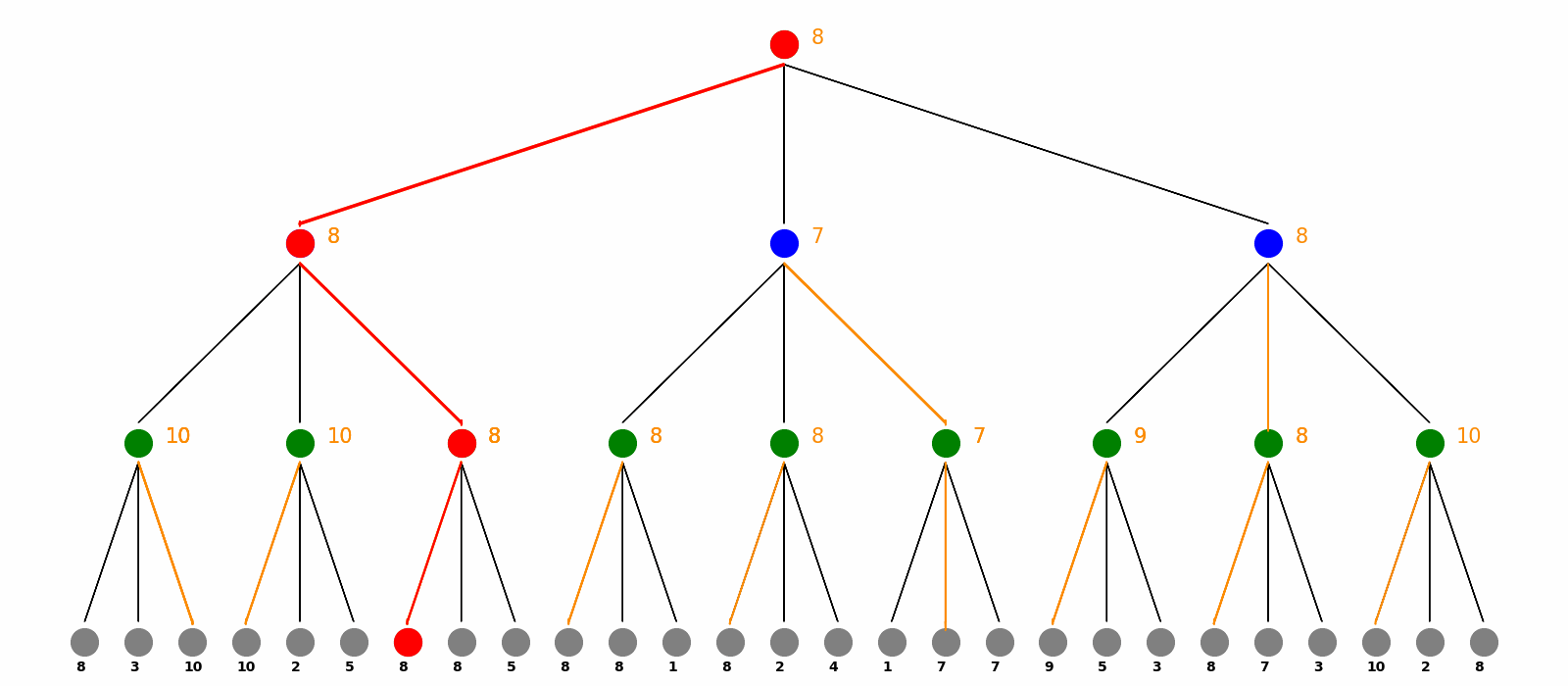
Markov Decision Process
A Markov decision process is composed of states, actions, transition probabilities and reward of states. It provides a mathematical framework for modeling decision making in situations where outcomes are partly random and partly under the control of a decision maker. At each states, we not only want to maximize the short-term reward but also long-term. So evaluating the value of a state is essential in MDP.
Value Iteration and Policy Iteration are algorithms where we have the full knowledge of the MDP (the transition probabilities are known), computing the optimal policy and value.
Value Iteration
Value Iteration start with arbitrary state value and use Bellman Update to update the values and pick the best policy.
Here is the visualization. Green nodes are state node and blue nodes are the environment with the transition probability on the arrow pointing to the next state. When we do Bellman Update on a certain state, it will be marked as red and a new value is updated on its left. The best action is labeled as red arrow. We do Bellman Update for rounds until it converges.
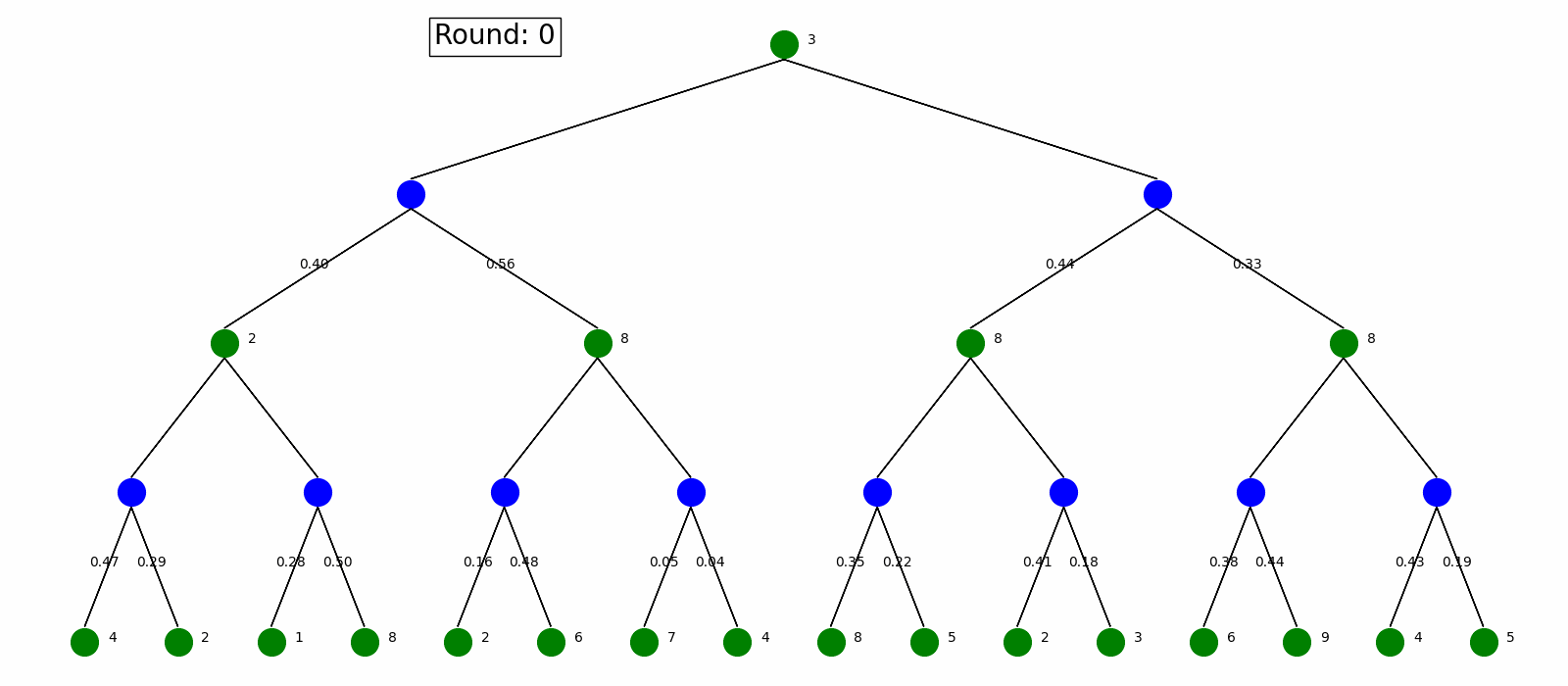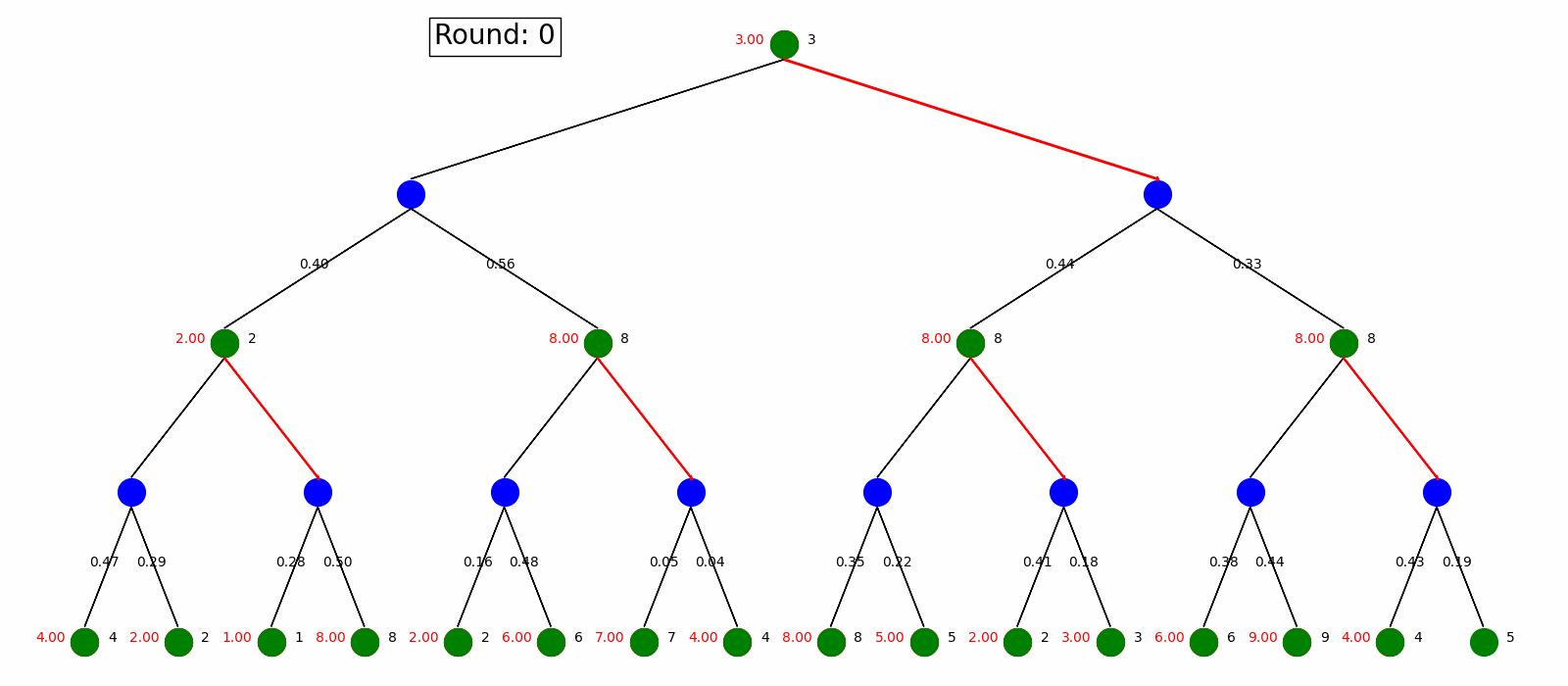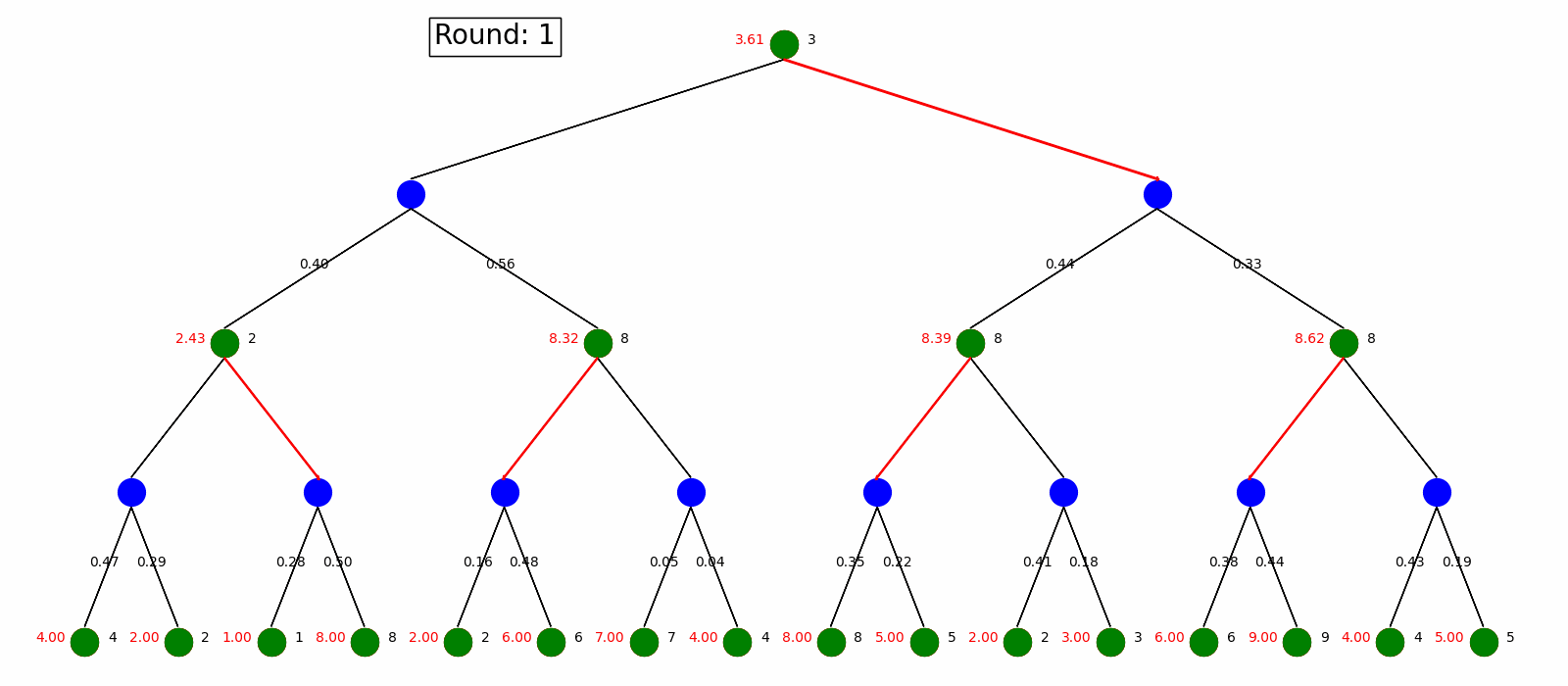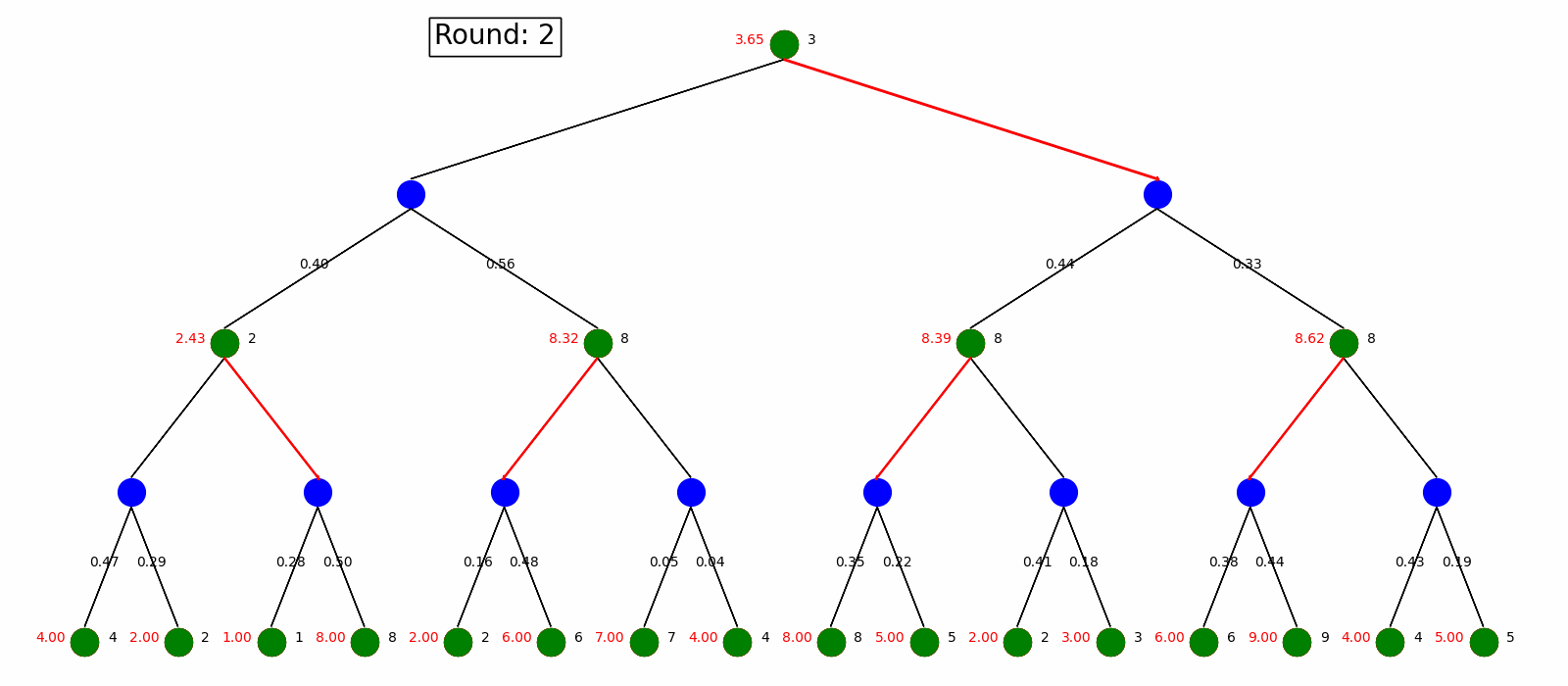
Policy Iteration
Policy Iteration starts with an arbitrary policy and solve the Bellman Equations to evaluate the values defined by the policy, then check each state to see if we can improve the max value. We keep doing this until the policy is fixed.
Here is the visualization on the same MDP as in the Value Iteration. Nodes and arrows are the same as in Value Iteration, where as every state start with an arbitrary policy and update it every round.
Comparison of Value and Policy Iteration
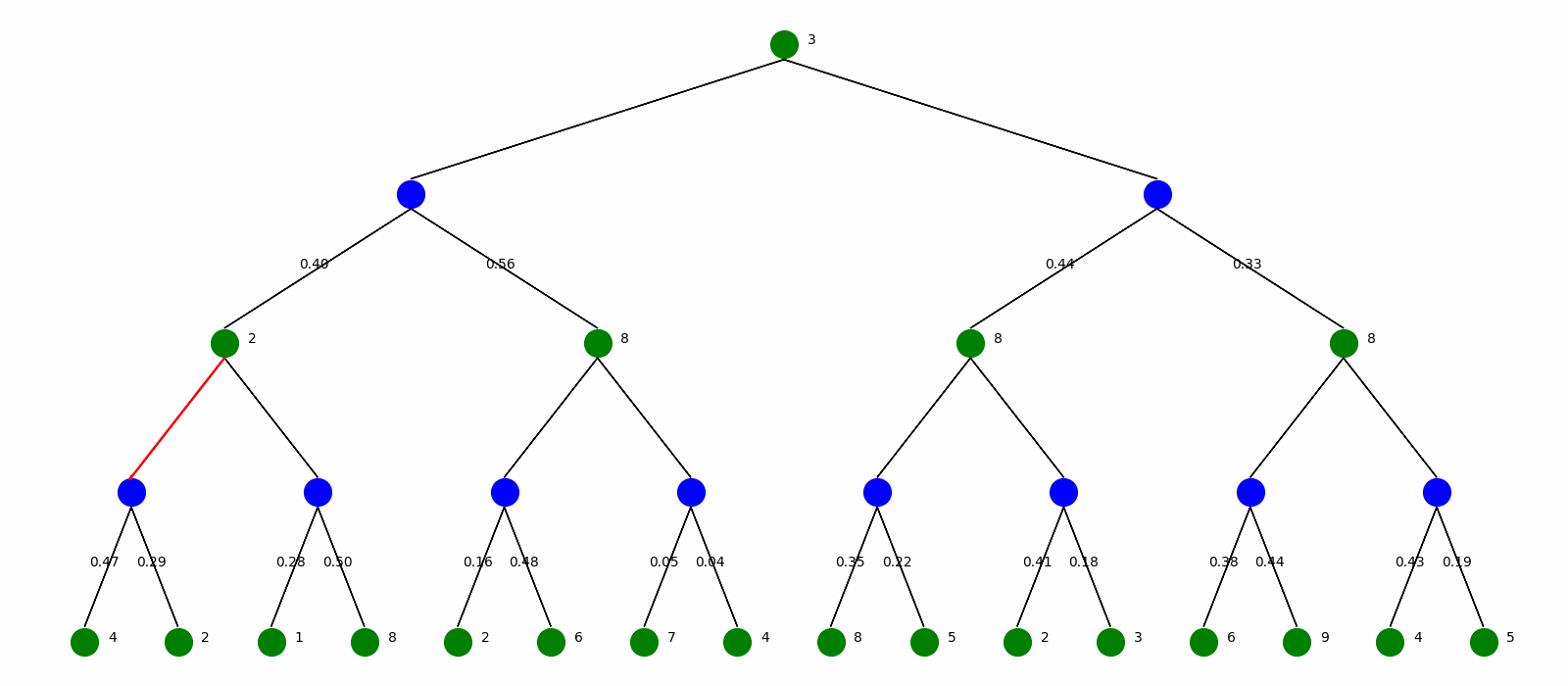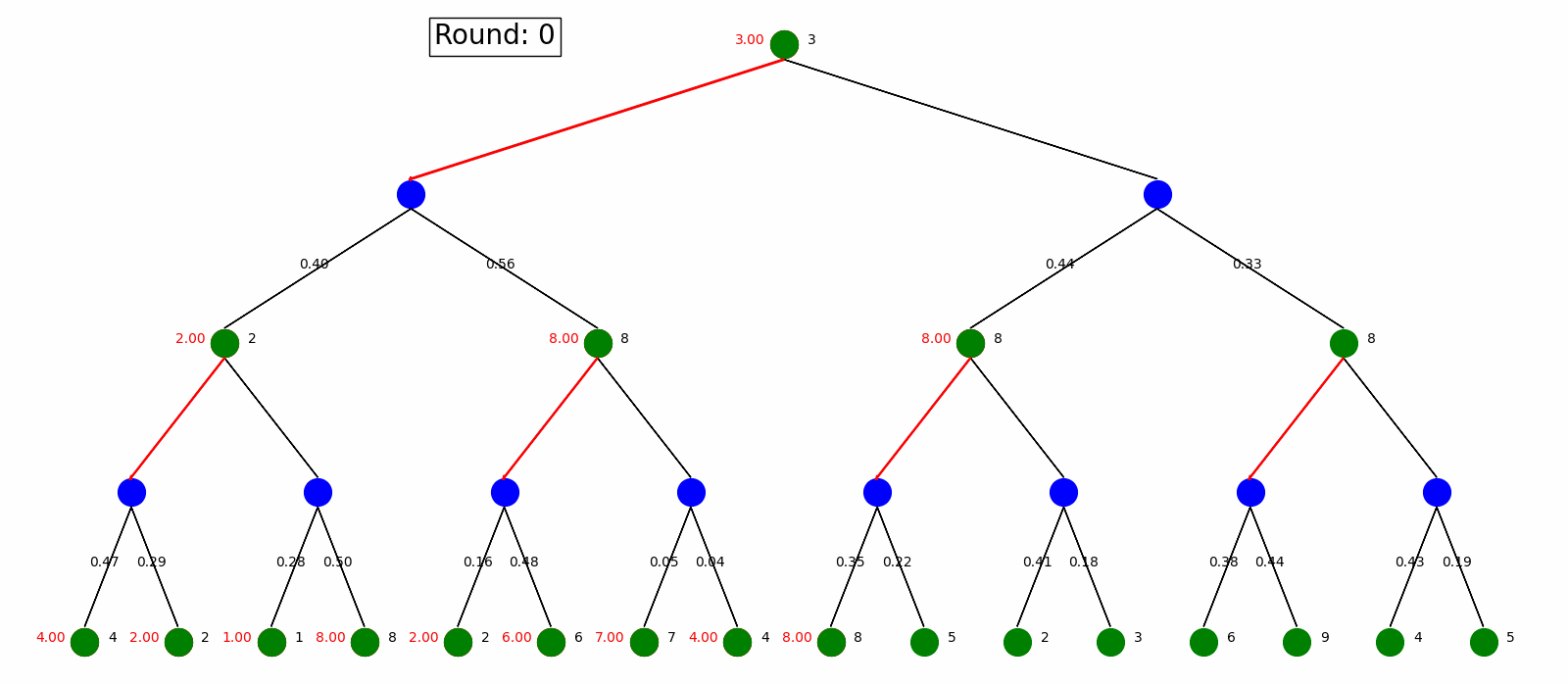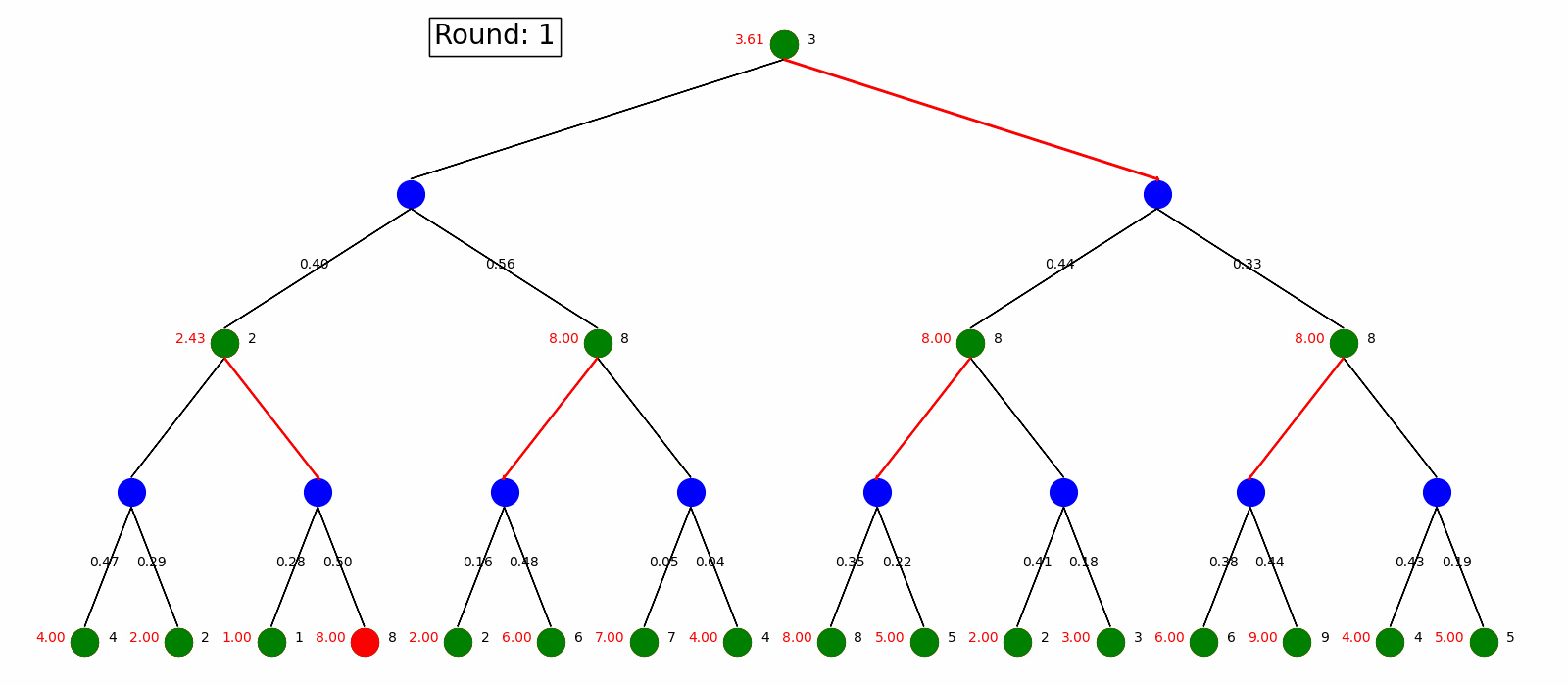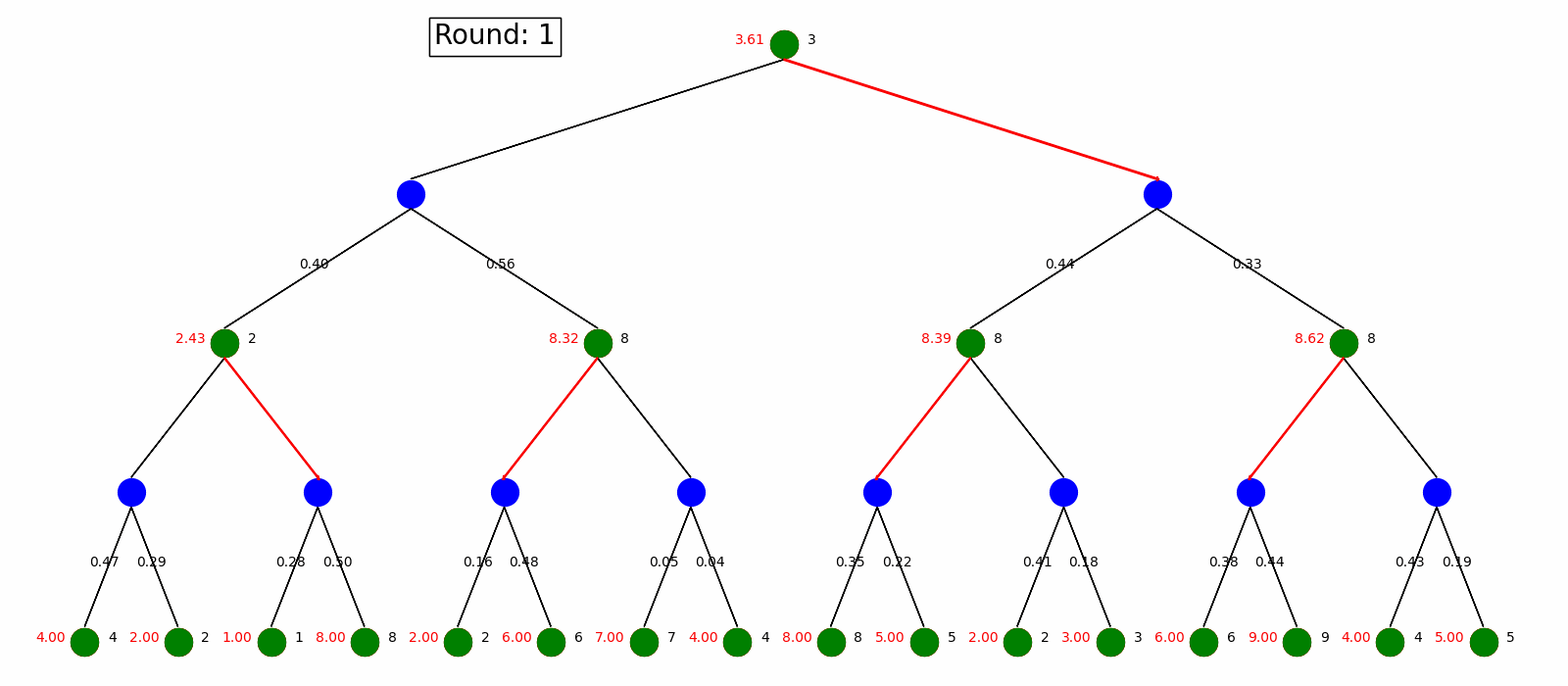
Here are the final state of the two algorithms:


As we can see from the final state of the two algorithms given the same MDP, the two algorithms output the same optimal policy, whereas the Policy Iteration may not output the final value of states because the algorithm stops when policy is stabilized.
MDP with Unknown Environment
In real world, we do not have the full knowledge of the transition probabilities in MDP. Can we improve or optimize a given policy without the transition model? There are three algorithms covered including Monte Carlo Policy Evaluation, Temporal Difference Policy Evaluation and Tabular Q-Learning.
Given a fixed policy, Monte Carlo Policy Evaluation and Temporal Difference Policy Evaluation can evaluate the value of each state by using sampling.
Monte Carlo Policy Evaluation
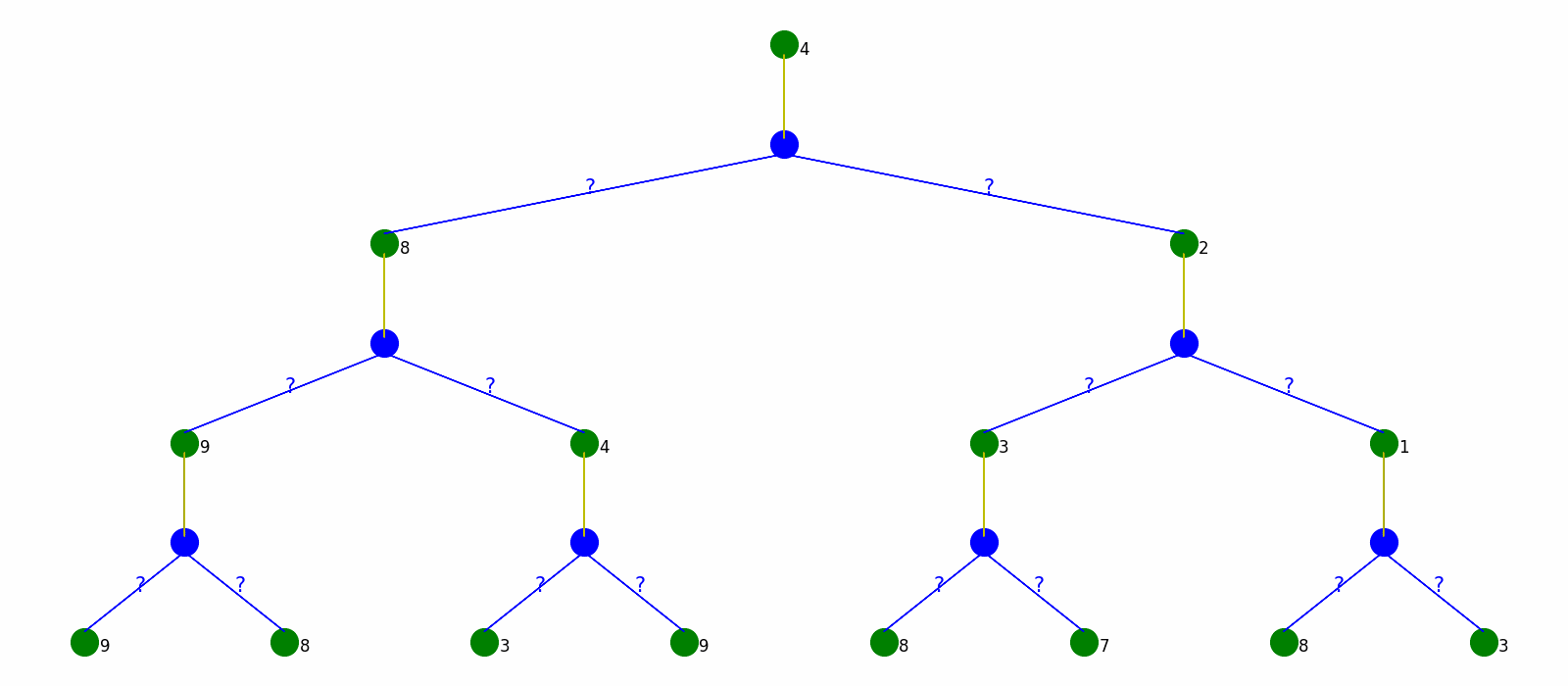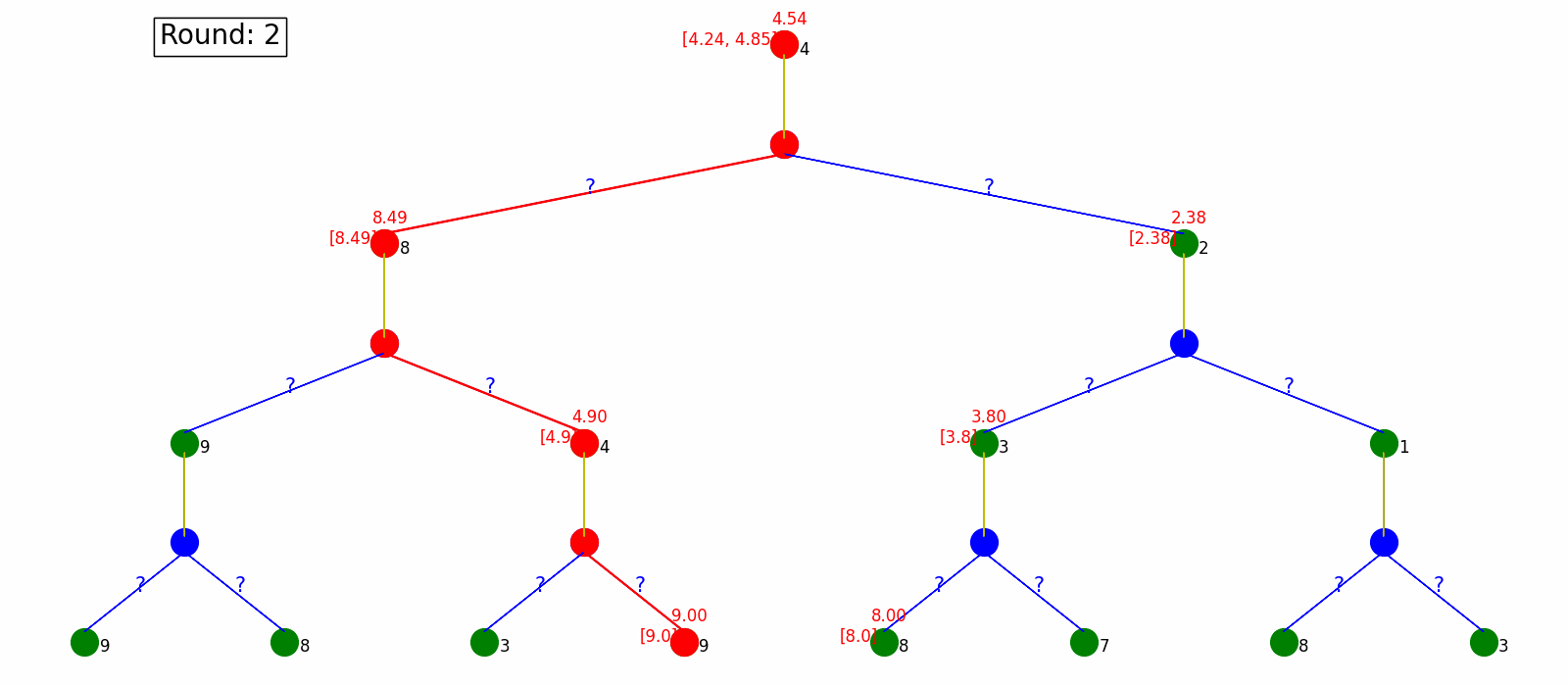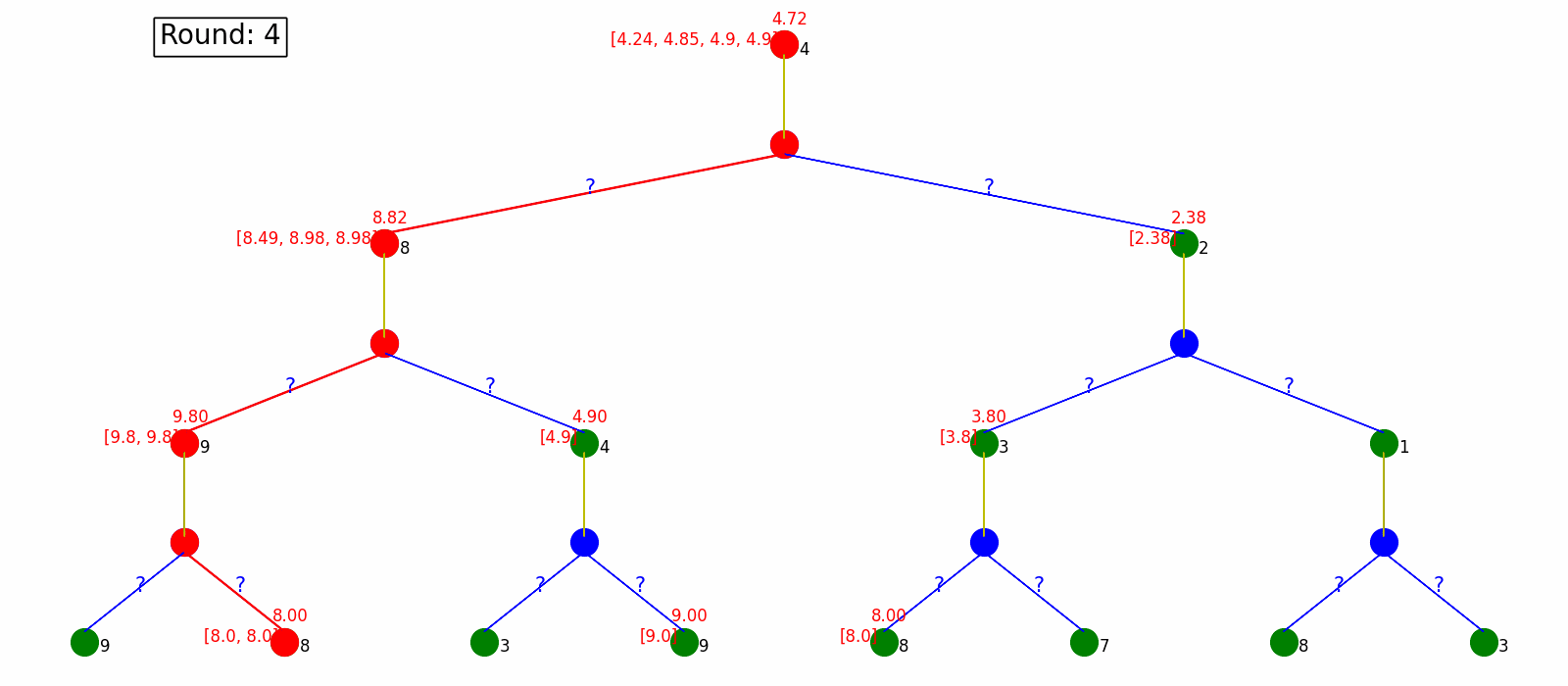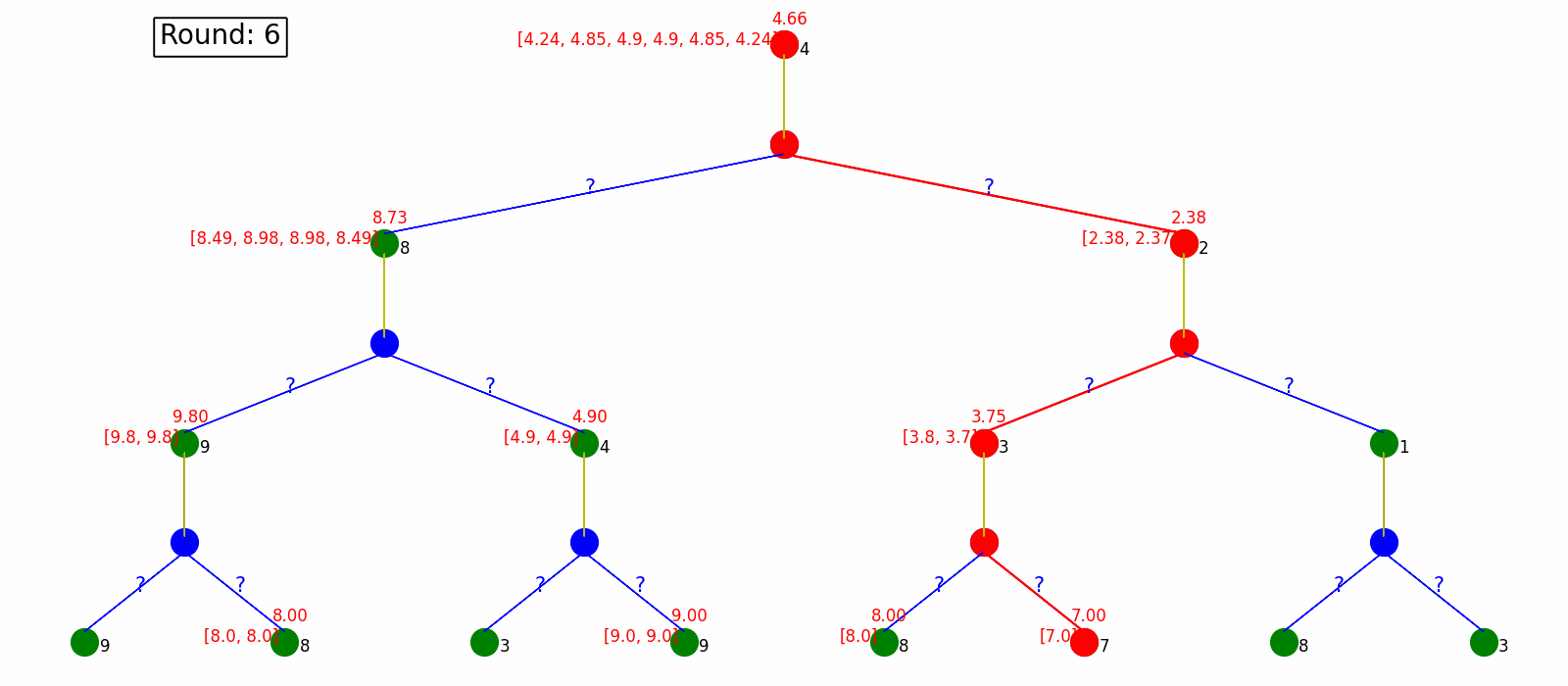
Monte Carlo Policy Evaluation simulates a lot of state sequences and use the average as the value of states.
The visualization is as follow. Every time the algorithm generate a sequence of states and calculate their values and use the average as the value of states. Note that every state only have one action which is the fixed policy.
Temporal Difference Policy Evaluation
Monte Carlo Policy Evaluating generate the whole sequence every time, which could be very time-consuming and even not practical when the MDP is infinite or has circles. Temporal Difference Policy Evaluation, however, utilizes the Bellman Equations and update on the way, without waiting for full sequences. In every step, it updates estimated values based on next sampled state without waiting for a final outcome.
Here is the visualization. Each round we only update state values based on the next state.
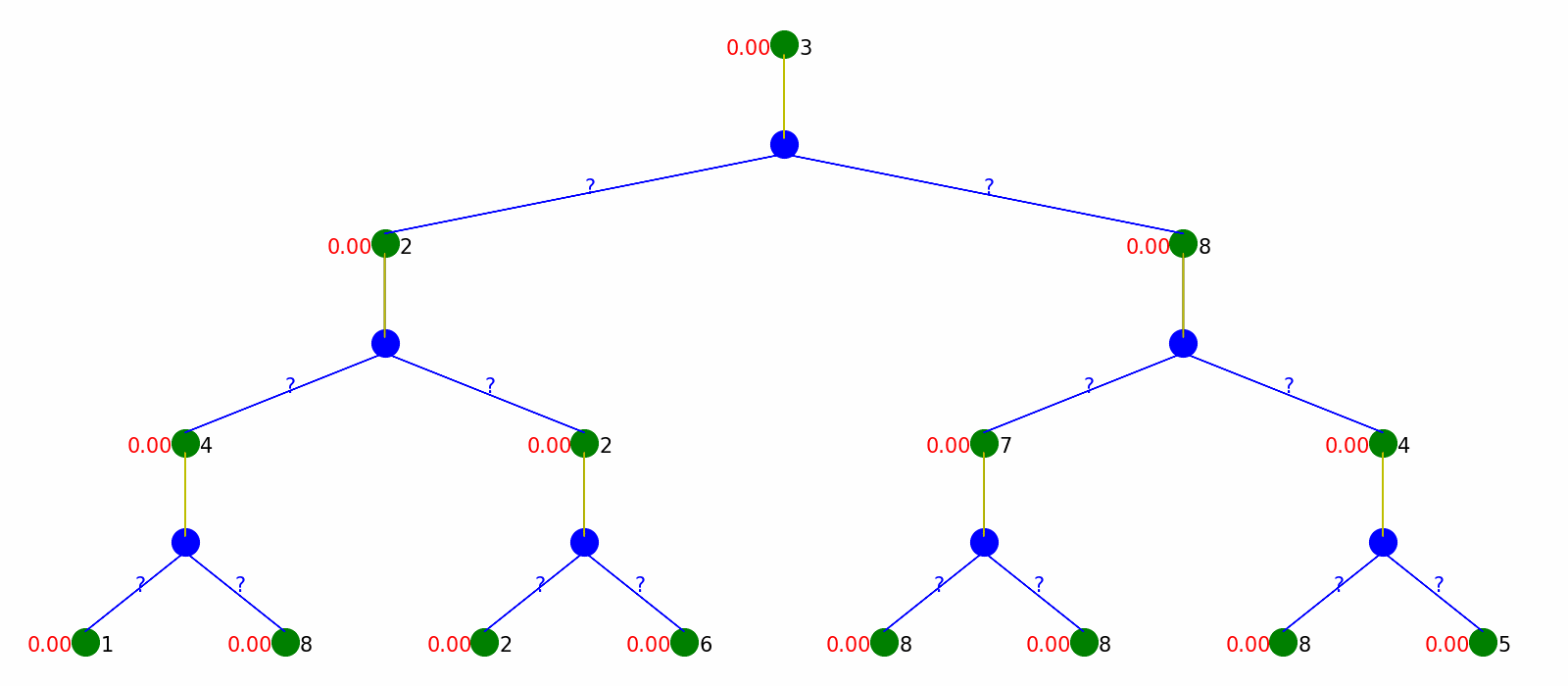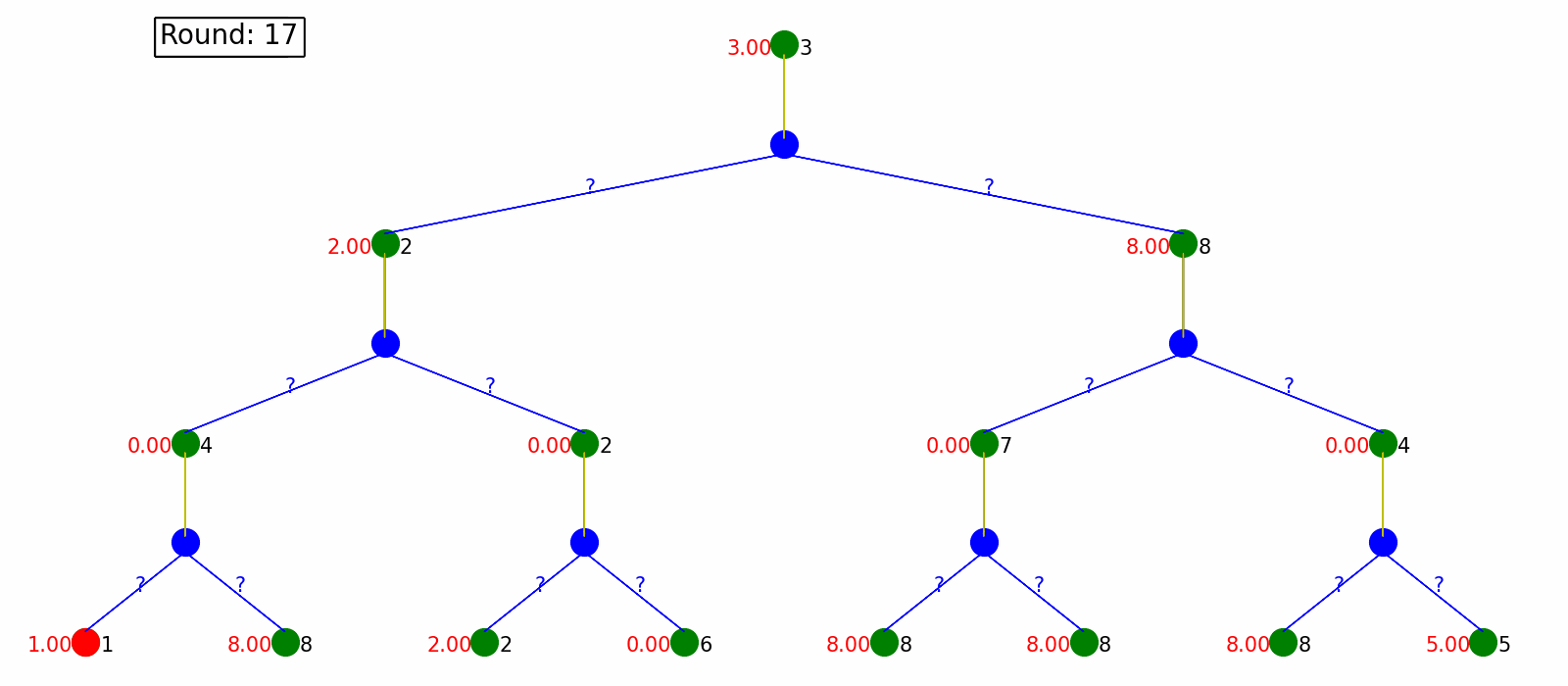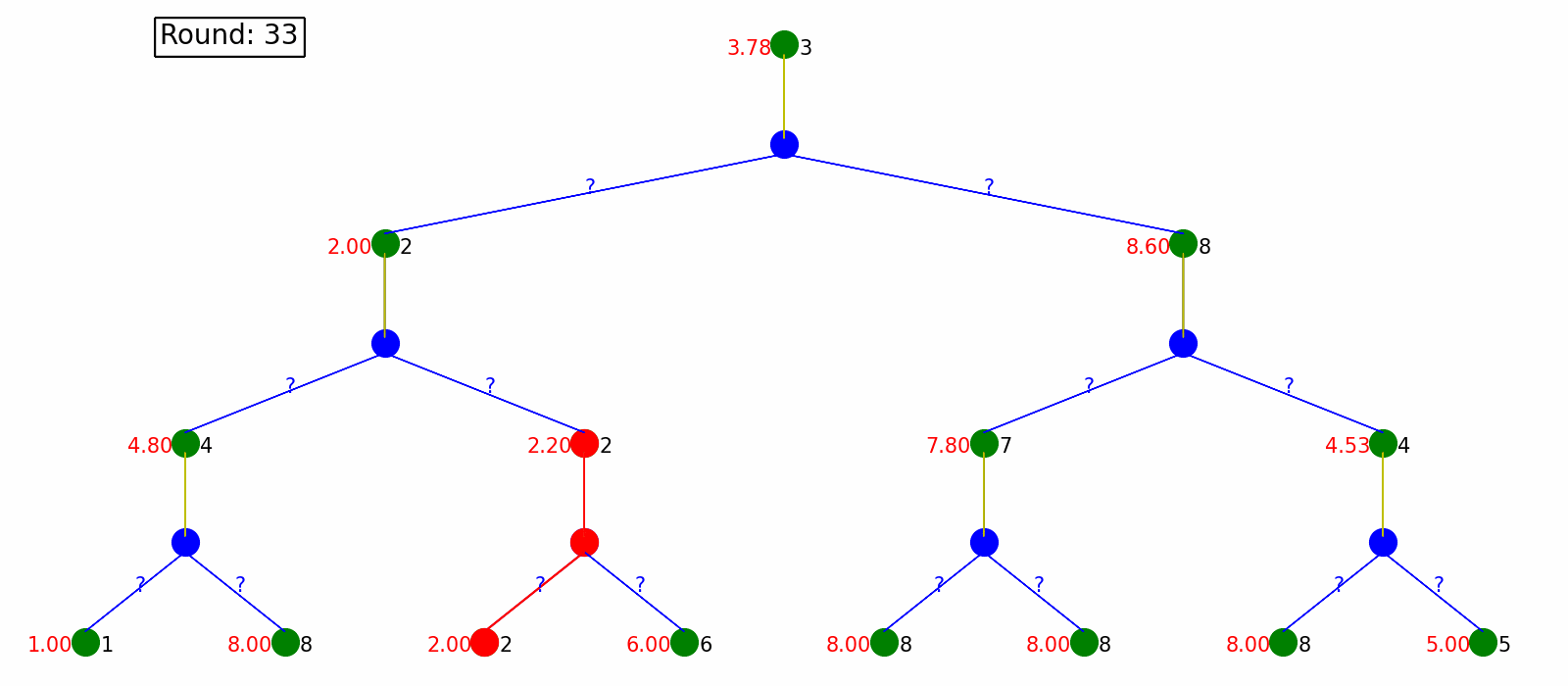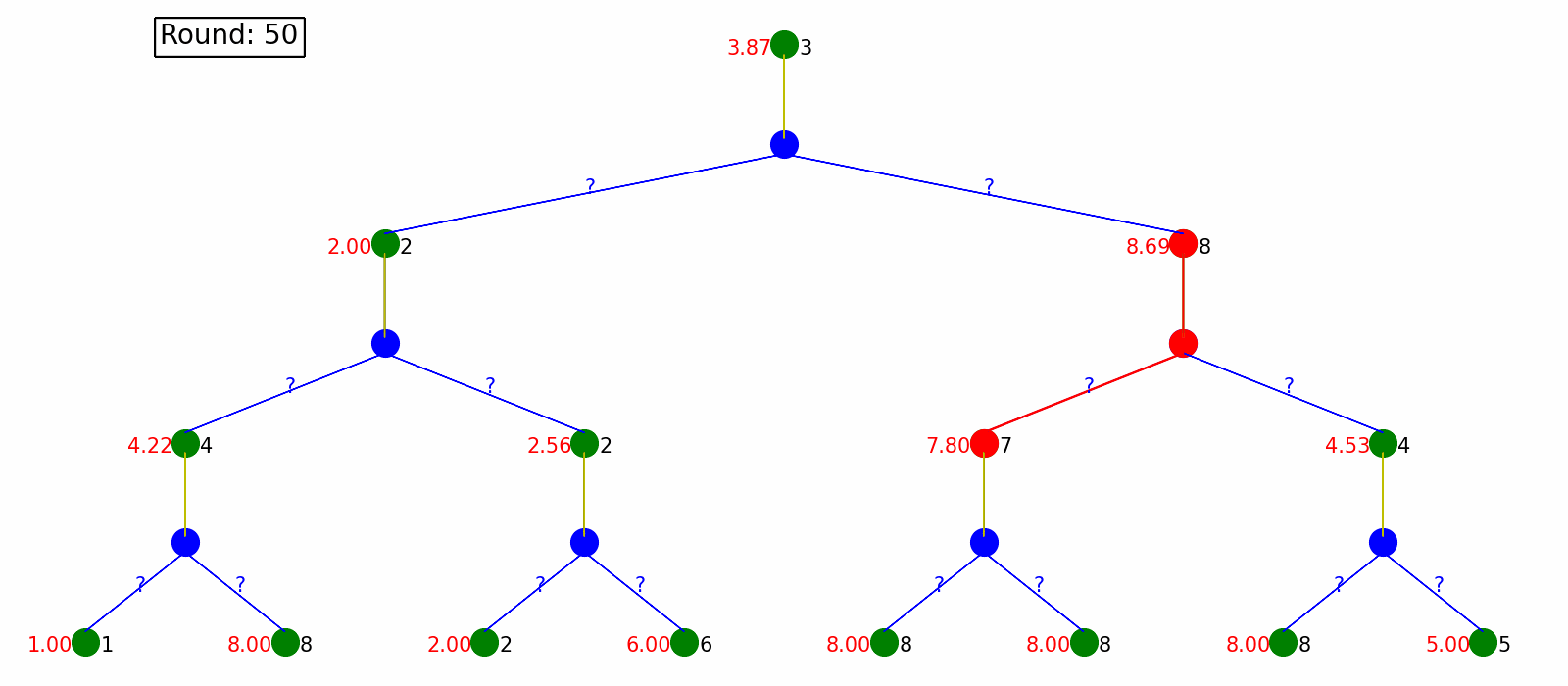
Tabular Q-Learning
Monte Carlo Policy Evaluation and Temporal Difference Policy Evaluation only estimate the state values given the fixed policy. But how can we take the best action in MDP without a transition model? Q-learning solves the problem of learning about the environment and improving policy at the same time.
It starts with knowing nothing and pick actions based on epsilon-greedy policy (choose either exploration or exploitation with epsilon probability), and then update the value of state taking certain action, which is Q-value. By updating the Q-value on the fly, the policy will provably converge to the optimal.
The visualization is as follow. We plot Q-value Q(s,a) in red next to the environment nodes. After Q-Learning, we can output a policy without knowing the transition model.
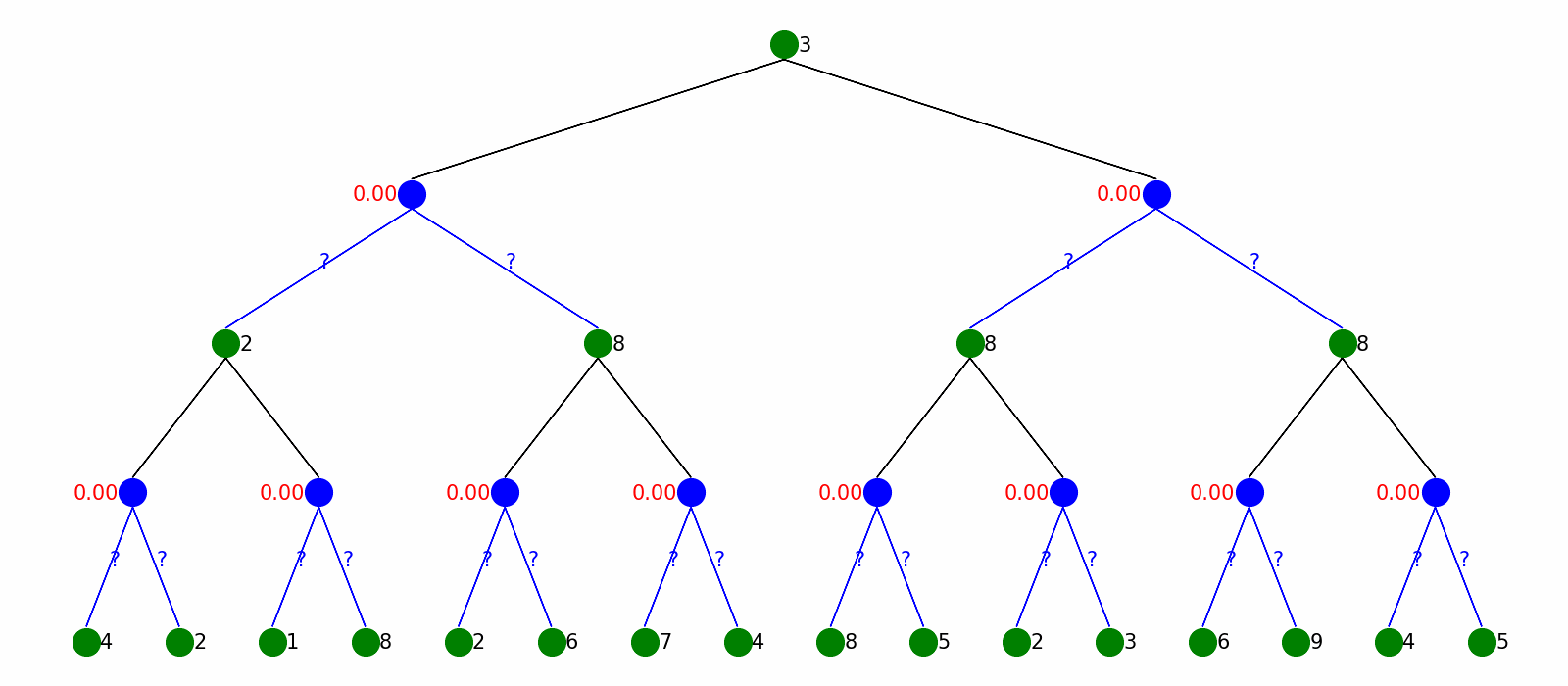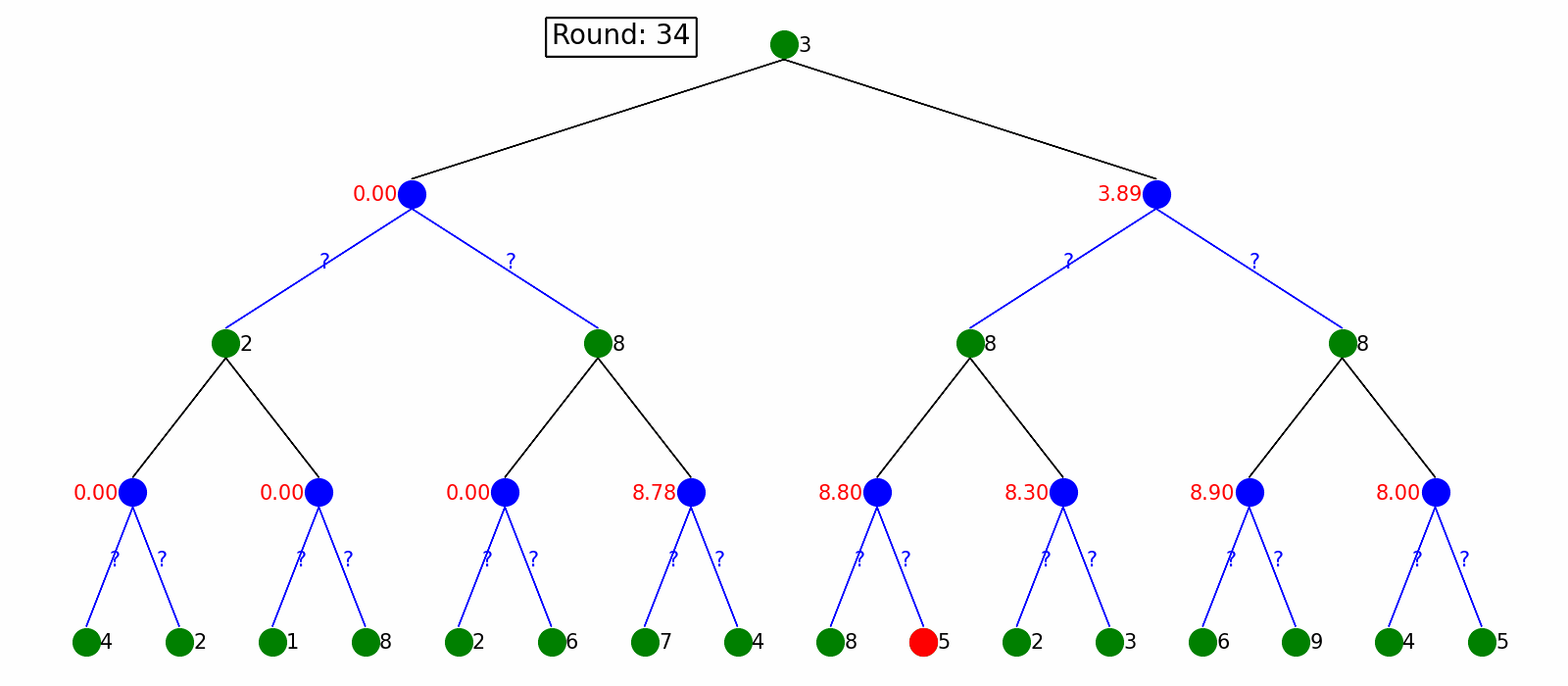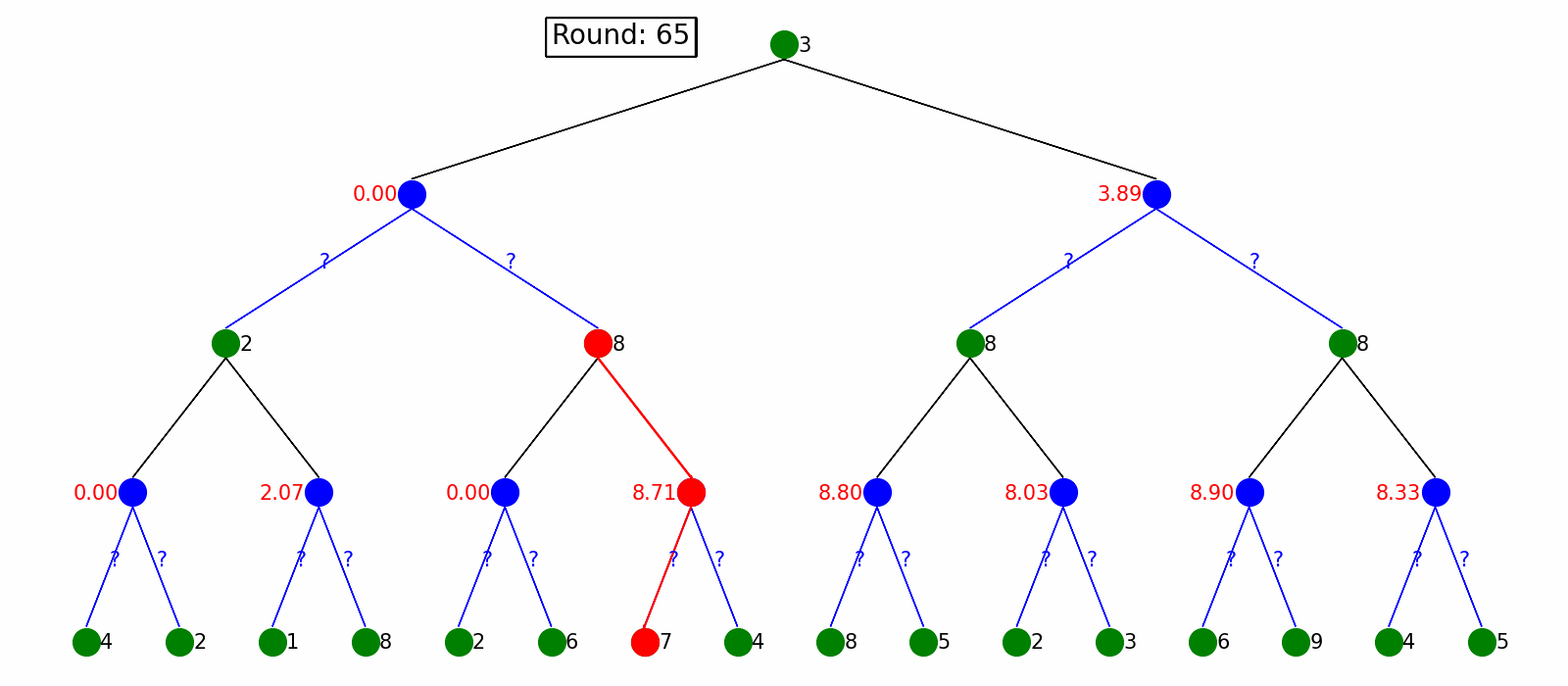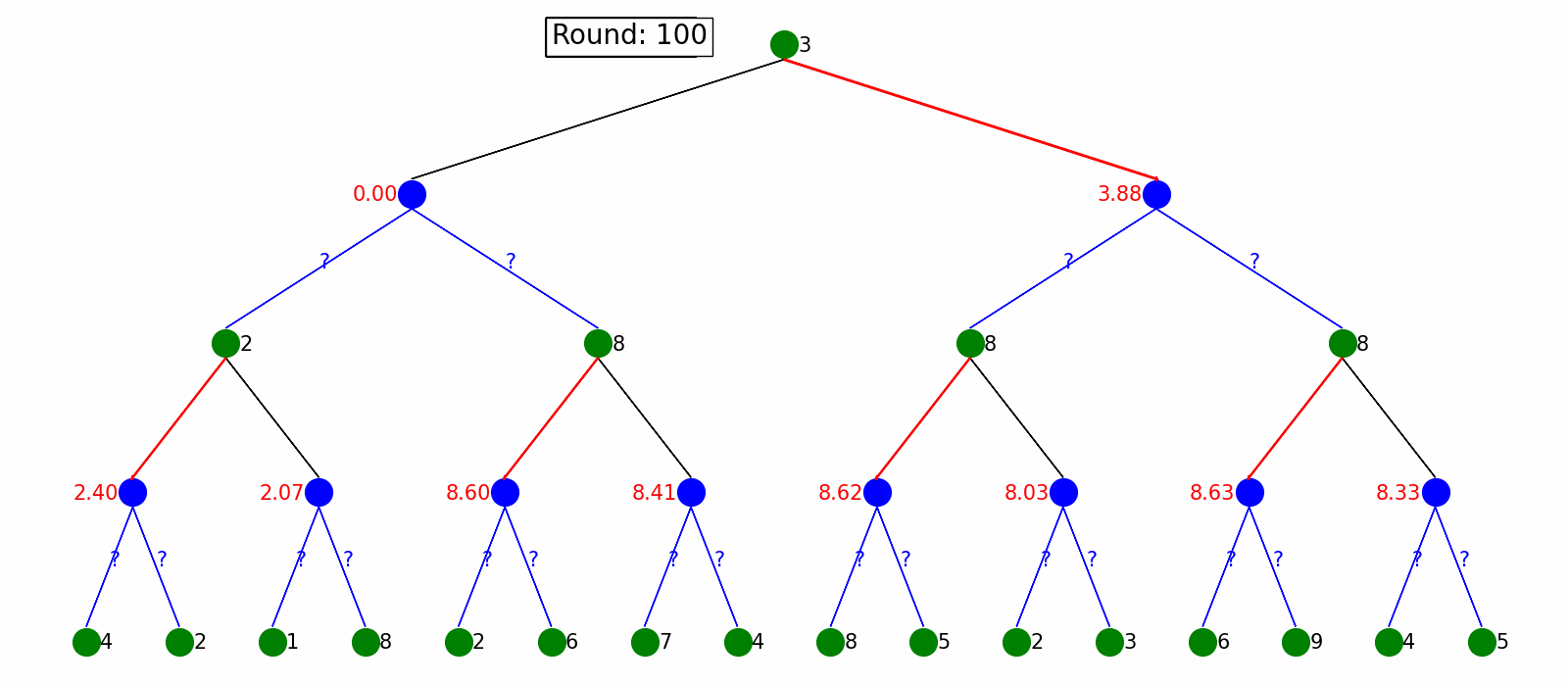
Deep Q-Learning
Tabular Q-learning store Q value for every state-action pairs. But we can use expressive function approximations to store values or/and policies. By doing this, we are no longer limited by table size or discretization and have better generalizability. Also we can directly manipulate the policies.
Deep Q-learning substitue the storting process in Tabular Q-learning with a deep neural network. It keep adding new experience in the pool of samples “Experience Replay” and every time takes a batch from the pool and fit a network to the new Q-value.
Here we display a more interesting example - a catching block game. A board on the bottom catches the falling block. We treat the current image of the game as state and the bottom board can take actions to move to the left or right. By doing deep Q-learning, we can get a smart AI game player.

Monte-Carlo Tree Search
Usually, the game tree can be extremely large like chess game which can take an impractical amount of time to do a full search of the game tree. Instead of growing game tree fully, we can use Monte-Carlo Tree Search to smartly grow game tree and ultimately make actions.
MCTS consists of Tree policy (selection and expansion of the tree), Default policy (simulation of the game) and backpropgation(update the value and number of visits of the game state).
We also use the tree structure to show how MCTS works. The green, blue, grey represents max player, min player and root player WON/LOST game state respectively. When backpropagating, we plot won/number of visited next to the node. After doing MCTS we can choose the best action for the current state.
